
Use cases, features, configuration, limits, integration with AWS Lambda
A good understanding of event-driven architecture and how to apply it is an important skill for developers and architects alike.
There are many AWS services that can help you when it comes to sending messages or dispatch events. In this deep-dive article we will focus on Simple Queue Service, SQS.
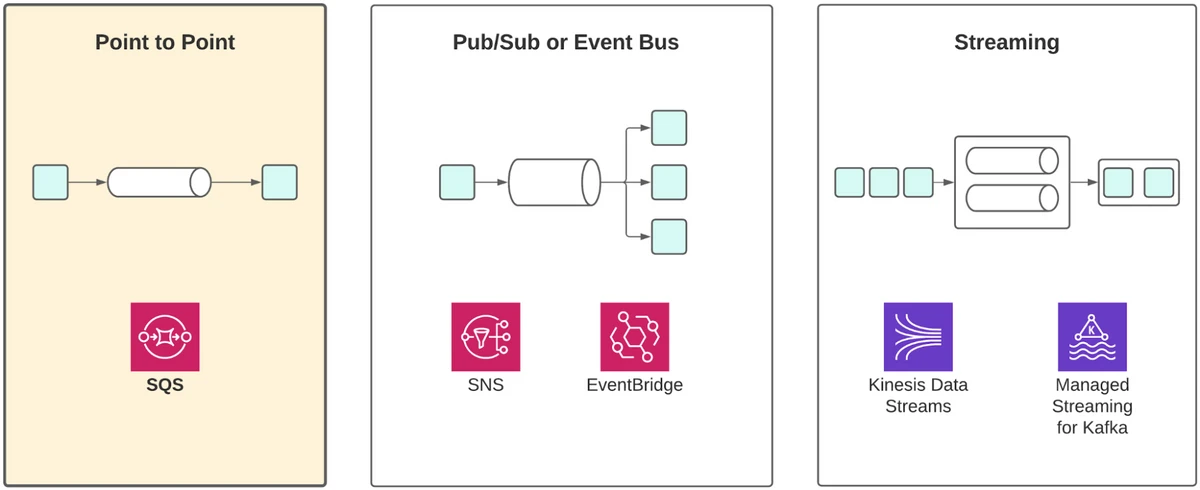
SQS is a point-to-point service. This means that messages sent through SQS are intended to be processed by a single receiver.
- Preventing tight coupling between producers and consumers
- Adding reliability, ensuring that the message is received and durably stored, even if the request processor is unavailable
- An SQS queue can deliver scalability in a simple way. The producer and consumer can scale at different rates, allowing you to handle variation in event throughput. In theory, SQS allows you to scale infinitely!
- SQS is a good choice for achieving cross-account or cross-region communication, so it suits cases where you have a geographically distributed application or you use multiple AWS accounts to isolate applications or components.
Let’s take a look at an example that demonstrates the effectiveness of SQS. Suppose you have a batch processing workload, like a piece of code that performs the task of image resizing. Users upload a JPEG to S3, and you want to process the image resizing job in a reliable and scalable way. We could periodically check S3 for new objects and process from a container or EC2 instance. Another option would be to trigger AWS Lambda directly from S3 Notifications.
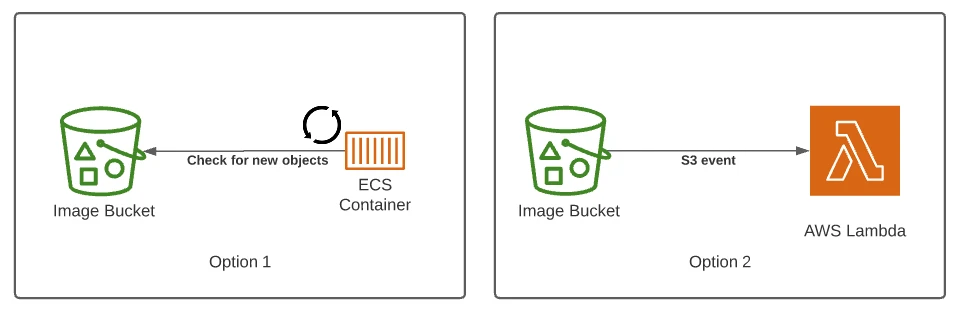
Both of these approaches are viable but they come with some complexity and some serious scalability and reliability challenges.
The containers or instances will need to keep track of some state. They will need to remember which files have been processed already and which files are new and yet to be processed. If there is only one instance, this can be done in memory, but if we want to have more than one instance we will need to have some way to share and synchronize the state between them.
Instances also need to scale according to the arrival rate of images. If new images are coming faster than they can be processed, the latency of producing thumbnails will only increase.
Additionally, we need to think about what happens when some processing tasks fail. Failed processing tasks should not be lost completely, ideally they should be retried and saved for investigation.
When using an S3 trigger for Lambda most of the concerns around scalability and distributing the work to multiple actors are managed for us by AWS, but we still have to deal with failure. What can we do if we constantly fail to process some images?
Adding an SQS queue to any flow such as this is a simple way to increase reliability and scalability.
- First, a reference to the image task is stored in SQS.
- A pool of processors takes a request from the queue and resizes the image. In the event of a failure, the message is “returned” to the queue and it will be eventually retried.
- The number of instances/containers in the worker pool can be scaled according to the number of messages in the queue.
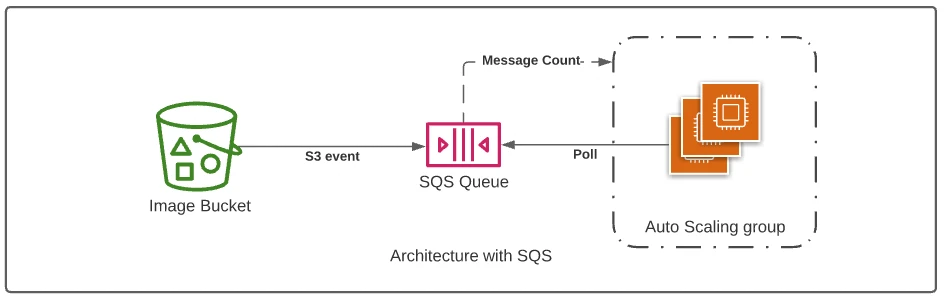
An SQS queue will work well even when we use Lambda functions as processing units, but more on this later!
Use Cases
The image resizing example extends to many more applications.
In enterprise IT, it’s common for batch processing workloads to perform calculation jobs, modeling, AI/ML workloads or data aggregation in a pool of workers. SQS is an ideal way to ensure scalability and reliability here too.
When it comes to event-driven architecture, SQS queues can also be employed as a communication pattern between microservices or between entire applications. Rather than relying on synchronous HTTP calls between services, a queue can be used. Again, this gives all the benefits of the service’s built-in availability, reliability and scalability.
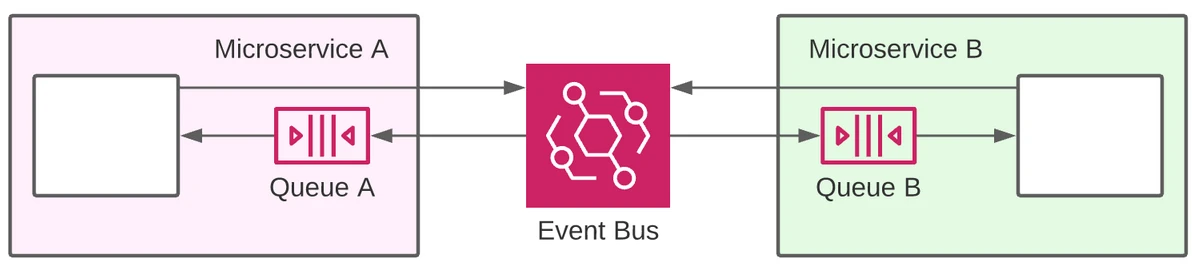
In this example, Microservice A and Microservice B need to communicate with each other. Rather than doing direct HTTP requests to each other, which will create a tight coupling between the two, they can simply dispatch events to an EventBridge bus.
Then, we can create an EventBridge rule to capture the events interesting for Microservice A and forward them to Queue A. Similarly we can create another rule for Microservice B capturing events and forwarding them to Queue B. The two services can then process messages from the respective queues with the benefits of built-in scalability and reliability that we mentioned earlier.
In fact, this design allows every service to consume messages in a decoupled way. The sudden unavailability of one of the 2 services won’t stop the other service from being able to publish an event. When the service is back online, it will find any new message in the queue and it will resume the processing.
Features
Let’s now run through the main features and characteristics of SQS.
SQS supports standard queues and FIFO queues.
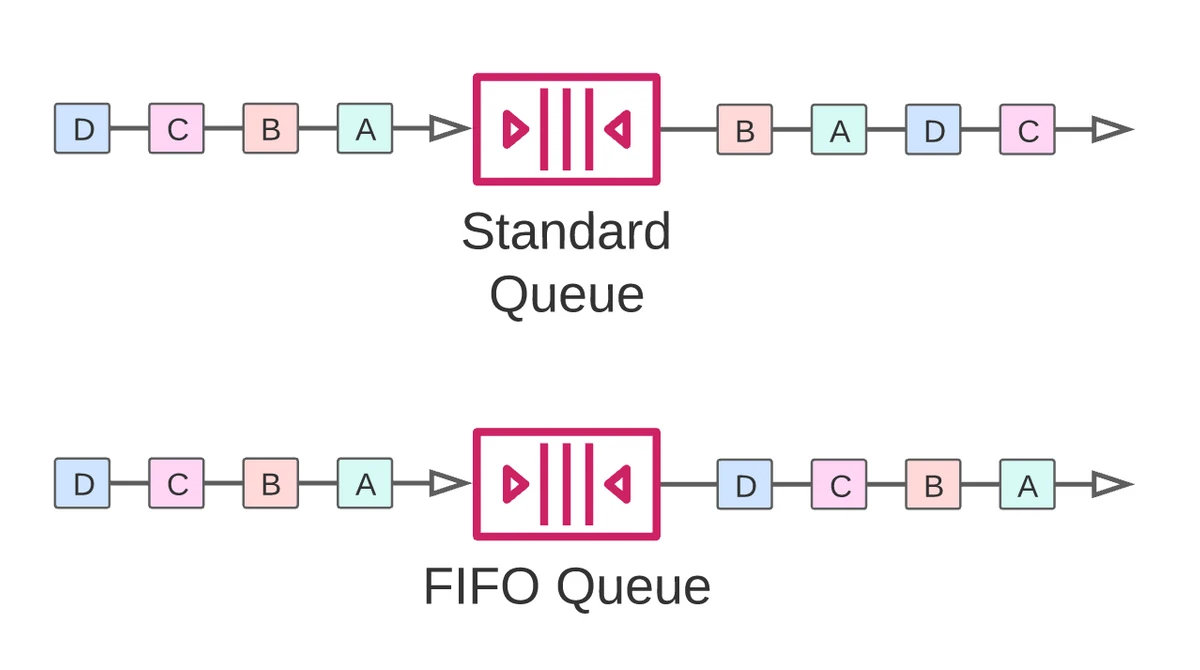
Standard Queues
Standard queues provide best-effort message ordering with at least once delivery. This means that you can expect occasions where messages may arrive more than once and, while they usually arrive roughly in the order they are sent, there are no strict guarantees.
FIFO Queues
FIFO queues provide strict ordering guarantees with exactly once delivery. With this method, you can be sure about the order of consumption and avoid duplicate deliveries. This comes with a tradeoff – the throughput with FIFO queues is limited by comparison.
Dead Letter Queues
Dead Letter Queues (DLQs) are a built-in feature of SQS. You can configure a separate SQS queue where undelivered messages can be sent. There is also an option to configure the number of delivery attempts made before passing the event to the DLQ. DLQ is a great feature to be able to “move out” messages that can’t be processed correctly because of repeated failures. This is something that can happen when there is a bug in the code. We might need to update the code and do a new release before the failed messages can be moved out from the DLQ and pushed back to the original queue.
Protocols
The protocol for SQS is an HTTP API. This differs from systems like RabbitMQ or ActiveMQ, where standards like AMQP and MQTT are supported. This may not matter in most cases, but interoperability can sometimes be a consideration.
Delays & Custom retry
You can configure a message delay of up to 15 minutes before they are delivered. This can be useful for things like custom retry logic for failed messages.
Encryption
SQS supports Server Side Encryption (SSE) with SQS-managed (SSE-SQS) or KMS-managed (SSE-KMS) keys for messages at rest. Encryption in transit, on the other hand, can be achieved using HTTPS or explicit client-level encryption.
Simplicity
Compared to complex, traditional message bus and queue applications, SQS has a smaller number of configuration options and features. True to its name, this level of simplicity is probably the most important feature of SQS! It removes a huge infrastructure and maintenance burden for architects and developers.
How to use SQS
Using SQS and its API is relatively simple with a few important considerations. Let’s go through the typical lifecycle of a set of messages.
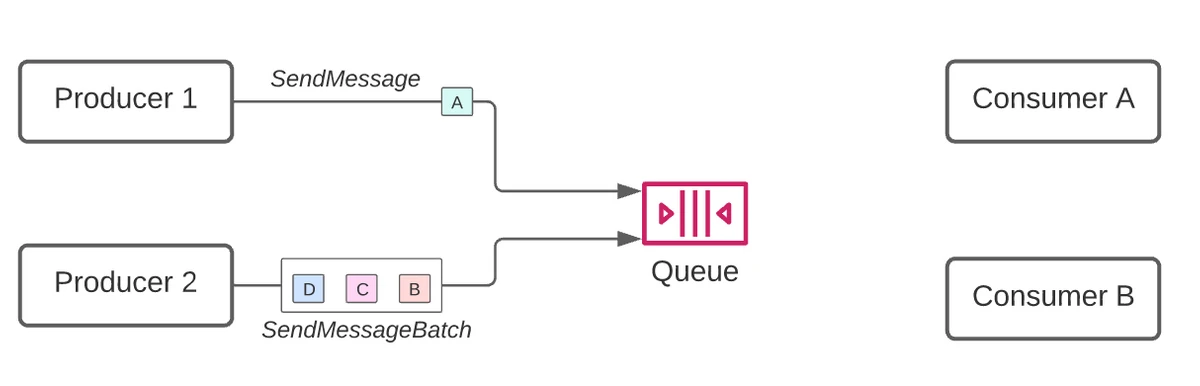
Sending
The SendMessage or SendMessageBatch API is called by the message producer. SendMessageBatch allows up to 10 messages to be sent at once
Receiving
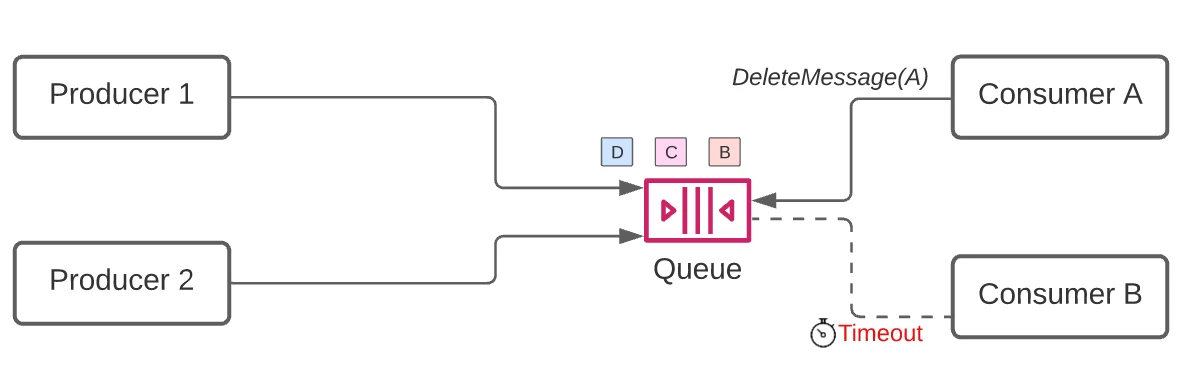
1. The consumer calls the ReceiveMessage API. This allows receivers to fetch up to 10 messages in a single call. Once this has happened, retrieved messages are not removed from the queue, but are instead marked as invisible.
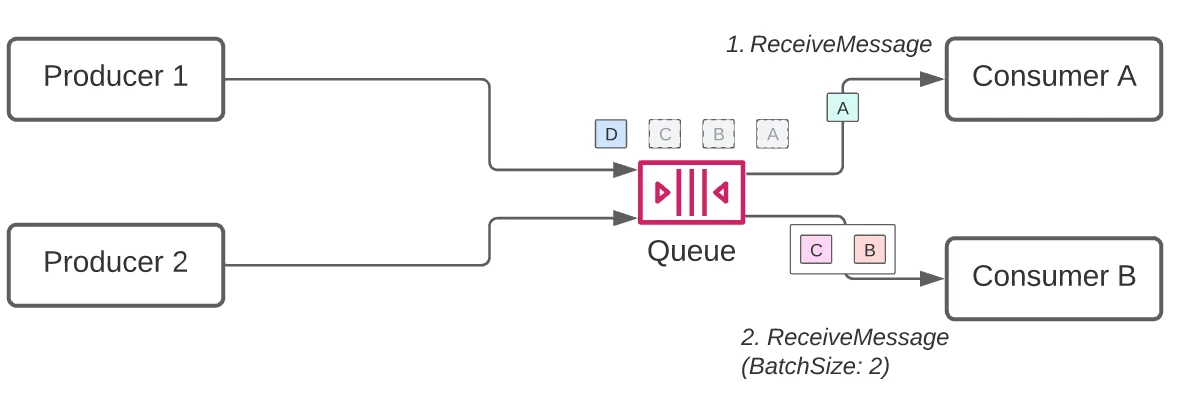
2. The consumer processes the message.
3. The consumer calls DeleteMessage. This is an acknowledgement to the SQS service that a specific message has been fully processed.
What happens if you forget to invoke DeleteMessage? The message will reappear in the queue after a configurable timeout and it may be consumed again by the same or another consumer!
The time it takes for the message to resurface in the queue depends on the queue configuration and the parameters to ReceiveMessage, so let’s look in detail and how SQS can be configured!
You don’t need to use the SendMessage APIs if you are using one of the services that already integrate with SQS to produce messages. API Gateway, SNS, EventBridge and Step Functions can all send messages to an SQS queue. Consumption of SQS messages is different since SQS doesn’t send messages, they have to be pulled. The only service that makes this easier is Lambda. It has an internal poller which is covered in the Lambda section below.
Queue Configuration
Once a consumer invokes ReceiveMessage, SQS will wait for a configurable period. If a Delete Message call is not received within this period, SQS assumes that processing fails and makes it visible again to other consumers. This period is called the Message Visibility Timeout and it is one of the more important configuration options to understand. Let’s take a look at these options in a bit more detail.
Message Visibility Timeout
Immediately after a message is received, it remains in the queue. To prevent other consumers from processing the message again, Amazon SQS sets a visibility timeout, a period of time during which Amazon SQS prevents other consumers from receiving and processing the message
Can be set to between 0 seconds and 12 hours, with a default of 30 seconds. MessageVisibilityTimeout can also be set for the queue and for each specific message.
Message Groups
FIFO queues maintain ordering within Message Groups. These are ordered streams within the queue, and can be used to give higher throughput, since consumers can process messages for different groups in parallel.
FIFO queue order guarantees are provided per Message Group ID. A Message Group ID is set per message.
Retention
The length of time messages are retained in the queue can be set to a value between 60 seconds and 14 days. The default is 4 days.
Queue Policy
SQS queues support a resource policy. This can be used to provide access to principals in the same way as an IAM policy. In addition, queue policies allow you to grant cross-account access to a queue resource.
Queue Policy
A message will not become visible in the queue until the message delay has elapsed. It can be set for the queue and per message. The default is no delay and the maximum value is 15 minutes.
De-duplication (FIFO queues only)
Message ordering in FIFO queues can only be guaranteed if you let SQS know how to detect message duplicates. You can set a queue to use content-based deduplication and messages content will be compared. Alternatively, you can provide a content deduplication ID in each message and that will be used.
Redrive and DLQs
A redrive policy configures a DLQ where undelivered messages will be sent. The policy’s maxReceiveCount specifies the number of attempts made before the message is deemed to be undelivered and sent to the DLQ.
High throughput (FIFO queues only)
While standard queue throughput is unlimited, FIFO queue throughput is limited since ordering must be maintained. The maximum throughput can be achieved with two settings:
- Set the FifoThroughputLimit to perMessageGroupId
- Set the deduplication scope to message group level
Limitations
SQS has very few limits and restrictions compared to any alternative. There is no limit to the number of messages that can be stored and there is no request limit for standard queues! There are a few limits to bear in mind, however:
- The message size is limited to 256KB. If you have a larger payload, you can store it on S3 and reference the object key in the message.
- FIFO queues allow you to make 300 requests per second by default. High throughput mode allows you to make 3000 API requests per second. Using batch APIs, you can send and receive up to 30,000 messages per second in a high throughput FIFO queue.
- The number of messages in flight (the state between ReceiveMessage and either DeleteMessage or the visibility timeout) is 120,000 for standard queues and 20,000 for FIFO queues.
Using SQS with AWS Lambda
Lambda receives messages from SQS queues using Event Source Mappings, the part of the Lambda service that polls event sources and passes batches of messages to function invocations. This same functionality can also be used for DynamoDB Streams, Kinesis Data Streams and Kafka. A really great advantage of Lambda’s SQS integration is the support for cross-account SQS access. This makes cross-account application communication setup much easier.
Lambda scales differently with SQS than it does with other services. Instead of starting with up to 1,000 concurrent functions as with other triggers, five batches are initially delivered concurrently and this scales by 60 per minute instead of the usual 500 per minute that you might expect from Lambda. Provisioned concurrency won’t help to change this. If the batch size is low and the processing time is long, this can be a serious bottleneck for performance. On the other hand, if you are processing large batches (up to 10,000 messages!) and the function duration is low, it’s not a problem.
You can configure how often batches of messages are sent for invocation based on any of the following settings.
- The maximum batch window, in seconds
- The number of messages in the batch
- The size of the batch payload (KB)
Always make sure to configure the visibility timeout of the queue for long enough for Lambda to retry as many executions as is possible, at least six times the function’s configured timeout. The function’s timeout should itself be long enough to process all items in the batch.
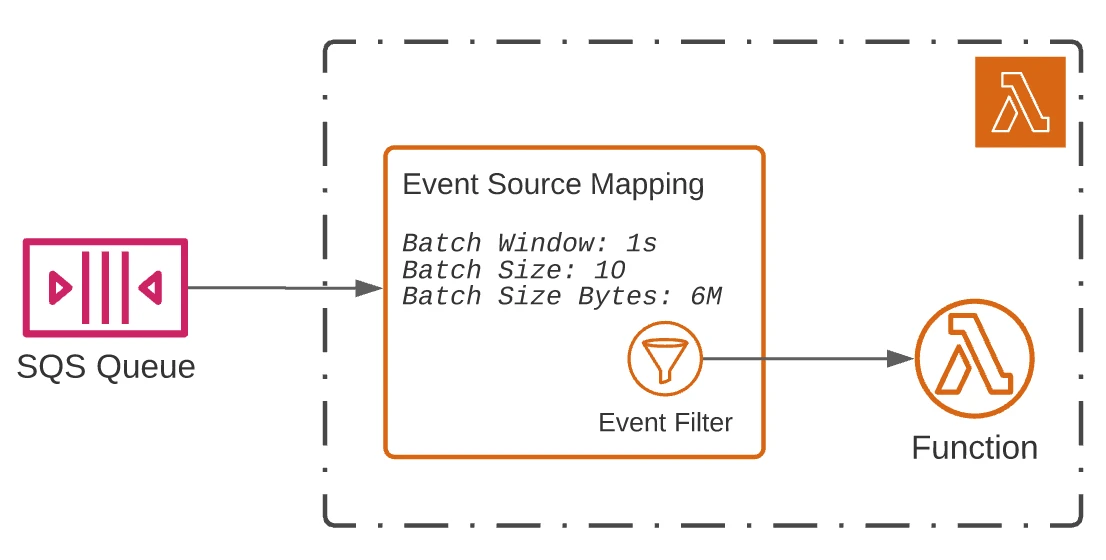
One of the latest features of Event Source Mappings is event filtering.
You can use this feature to specify up to five filter patterns, excluding non-matching messages from reaching the Lambda function.
By reducing the number of messages processed by a Lambda function, you have the potential to save cost and avoid filtering within the function’s own logic.
It’s worth knowing that when you filter out SQS messages, they are not just skipped but also deleted from the queue. This can have some strange consequences!
Imagine you have two functions, each triggered from the same queue. If a message is filtered out by one function’s event filter, it is deleted and cannot reach the other function, even if that function would filter it in! Event filters only really make sense if you have no control over the messages arriving into a queue, something that is fairly rare in cases where SQS is used.
Wrapping Up
SQS is one of the most powerful, yet simple AWS services.
It is one of the best ways to add durability and scalability to applications with very little effort.
The number of configuration options are minimal so it’s easy to get started but still flexible enough to be applied in many critical workloads.
If you are starting to use AWS and SQS and you are looking for professional help, get in touch with the team at fourTheorem, we’d be happy to assist!

")
