Data Platform
Rapidly pilot and explore the advantages of modern data mesh architecture within a risk-free environment.
What is a Data Mesh?
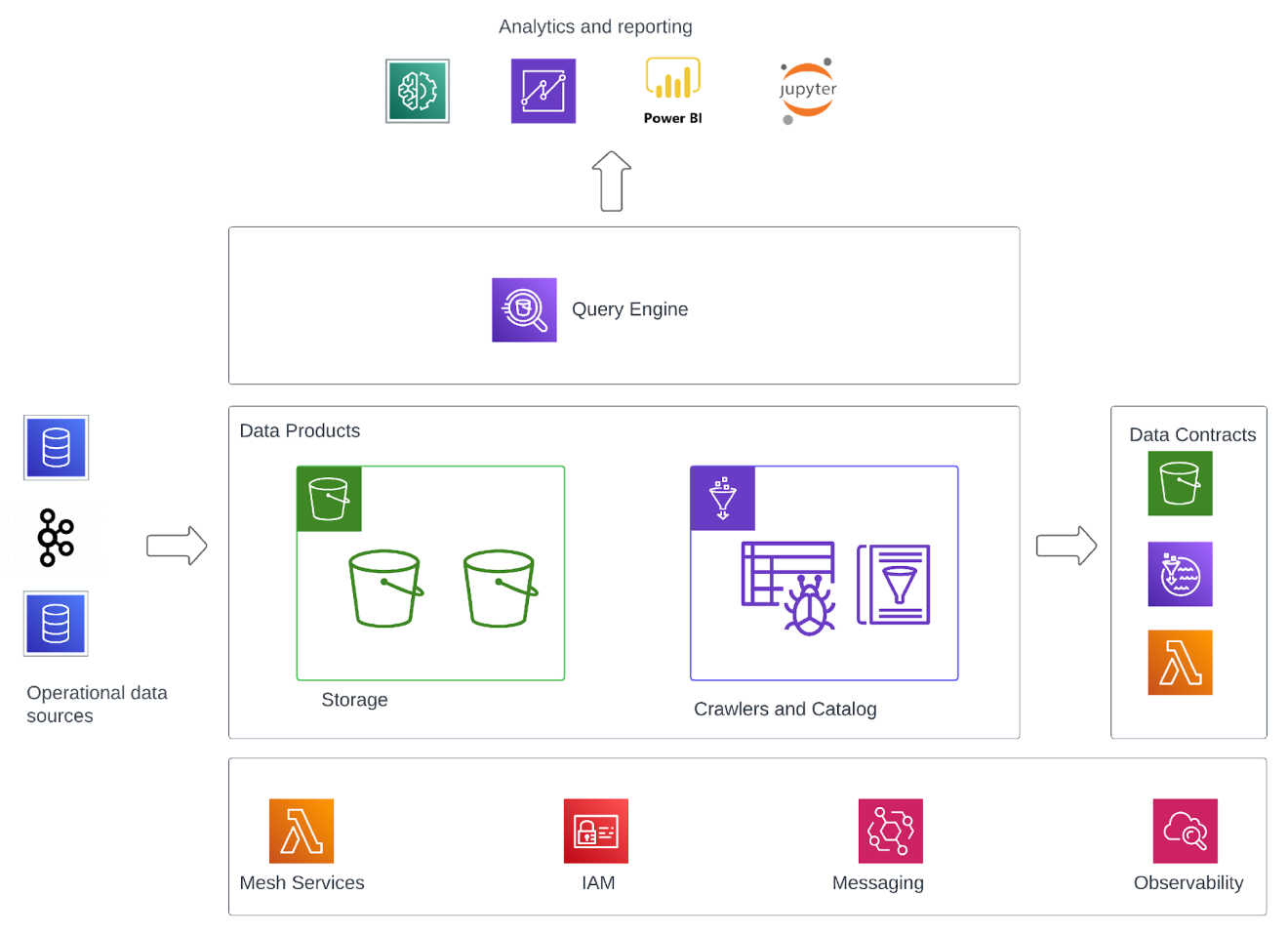
A Data Mesh is a decentralised architecture designed to manage and share analytical data at scale. It emphasises treating data as a product, with ownership by domain experts, federated governance, and a shared data platform.
By adopting a Data Mesh, data-heavy organisations can address challenges such as bottlenecks caused by overburdened centralised data teams, performance issues from running analytics on operational databases, inefficiencies from excessive ETL jobs, poor data quality and governance, siloed data, and fragmented or “accidental” data architecture.
For organisations facing challenges managing and scaling data, planning migration and modernisation programs, or seeking to unlock innovation and GenAI use cases.
Benefits
Remove Bottlenecks
From central data teams by devolving responsibility for data products to domain experts.
Evolutionary Architecture
Decoupled & decentralised architecture means that the platform can flex and scale with the business.
Zero-ETL Integration
Published data products can be consumed in-place without copying.
Improved Observability
The platform monitors data production and consumption metrics.
Increased Agility
Autonomous domains can run faster with higher agility.
Data Provenance
The platform can track lineage and improve auditability.
Improved Data Quality
Data is published and described by decentralised expert teams.
Governance & Security
The platform controls access policies and contracts centrally.
Data Platform Accelerator
Rapidly pilot and explore the benefits of a data mesh in a risk-free environment, effectively overcoming analysis paralysis.
Leverage our proven templates and expertise in leading data services—including AWS S3, AWS Glue, Athena, Redshift, AWS Lake Formation, Amazon DataZone, Dremio, Snowflake, Databricks, Power BI, and QuickSight.
With support to incrementally rollout the Mesh across the enterprise.
How it works
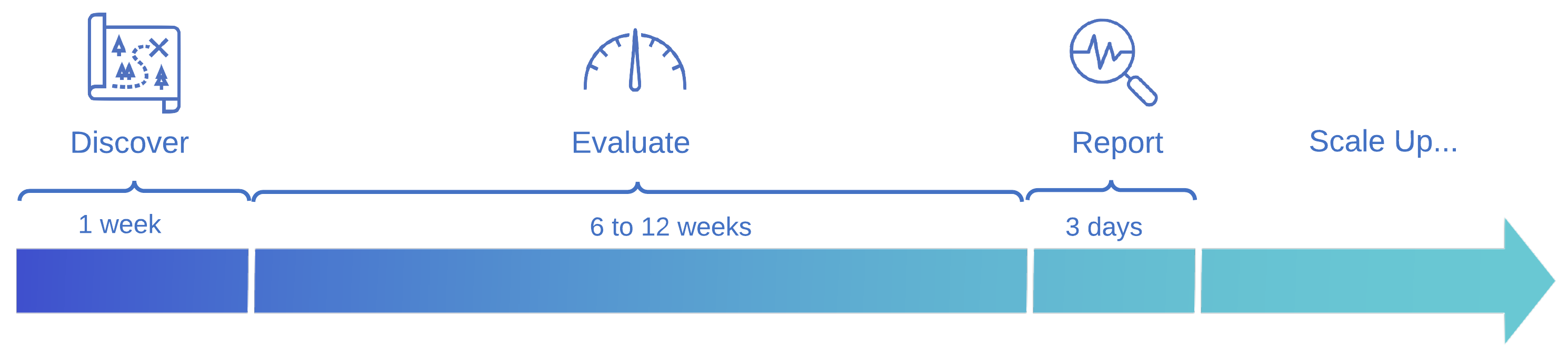

1. Discover
The accelerator begins with a discovery workshop. Following this we work with you to understand the data landscape of your organisation and identify pilot data products and business use cases.

2. Pilot
During the pilot phase, we deploy our Mesh Accelerators to rapidly build out a self-service platform on top of AWS native data services. We work collaboratively with internal customer teams to define data contracts and enable the creation of pilot data products. This is an iterative and transparent process that is focused on delivering the identified business use cases

3. Plan
The learnings from the pilot phase are used to develop a full incremental rollout and adoption plan for the Data Mesh tailored to your organisation as a key deliverable from the accelerator.

4. Roll Out
Post the accelerator, we support the incremental rollout and wider organisational adoption of the mesh through strategic consultancy and/or hands-on implementation.
Case Study – Financial Services Customer
The Problem: A data-heavy global financial services company faced numerous data challenges due to rapid business growth, hindering efficiency and agility. Additionally, there was a recognised need to modernise the application portfolio to adapt to evolving business requirements.
The Solution: Establish a central, self-service data platform that could accommodate the organisational domain structure and devolve responsibility for data to specific domains. Improve observability and data lineage, as well as democratise access to data across the organisation.
The Outcome: The creation of an evolutionary, event-driven platform maximised team autonomy, fostering innovation and agility within the organisation.