
This article originally appeared on LinkedIn.
If you haven’t heard the word “observability” used in your IT organisation, that’s about to change. What does it mean? The term observability comes from control theory in engineering and it refers to the ability to know what’s going on inside a system by looking at its outputs. The popularity of this idea within software engineering can be linked to the trends of cloud computing and distributed systems – software made up of many small components, or microservices. It helps reduce the number of unknown-unknowns that can happen under the hood.
Observability in the cloud
So what has observability to do with cloud and microservices? Firstly, companies are moving IT systems to the cloud en masse so they have less infrastructure to build and maintain. Cloud providers have become experts in building and scaling hardware and virtualisation solutions so we don’t have to. This trend is continuing, with providers like AWS and Azure moving higher up the stack and delivering automatically scalable storage, compute and analytics. By adopting cloud in the right way and adopting these managed cloud services, you can free up large amounts of cost and engineering time, ultimately reducing business risk.
The rise of microservices
The availability of on-demand cloud computing has also enabled architects and developers to build systems made of small, single-purpose components. These typically run on cloud-hosted container platforms but even this pattern is being disrupted by the emergence of serverless compute, AWS Lambda being the most prominent example so far. Microservices have been enormously popular for a number of compelling reasons:
- They allow teams to focus on specific areas of functionality within the system without having to constantly consider the complexity of the big picture.
- They are simpler and faster to deploy in isolation, making the deployment of features and changes less risky.
- Each component is independently scalable and isolated, making the system more robust and capable of handling large variations in traffic.
- By separating the system into distinct components, it’s easier to prevent the kind of system decay that we have seen in the past where any change becomes slow and bugs take too much time to resolve.
- Having multiple small components often facilitates better organisation of teams and separation of work, especially for bigger companies.
The challenge with microservices
The combination of cloud computing and microservices can be highly efficient, but what about the drawbacks? By taking a high level look at the component model for modern applications compared to traditional monoliths, you might have an idea where the trade-offs are.
With a classic monolith, it was certainly easier to know how data travelled through the system and which component may be broken. A modern application made of many, distributed components can be more complex to understand without the right tools. Data and information about the behaviour of your system is therefore fragmented. This is where observability plays a critical role. We can ensure that our components generate the right kind of outputs to facilitate troubleshooting, development and business understanding.
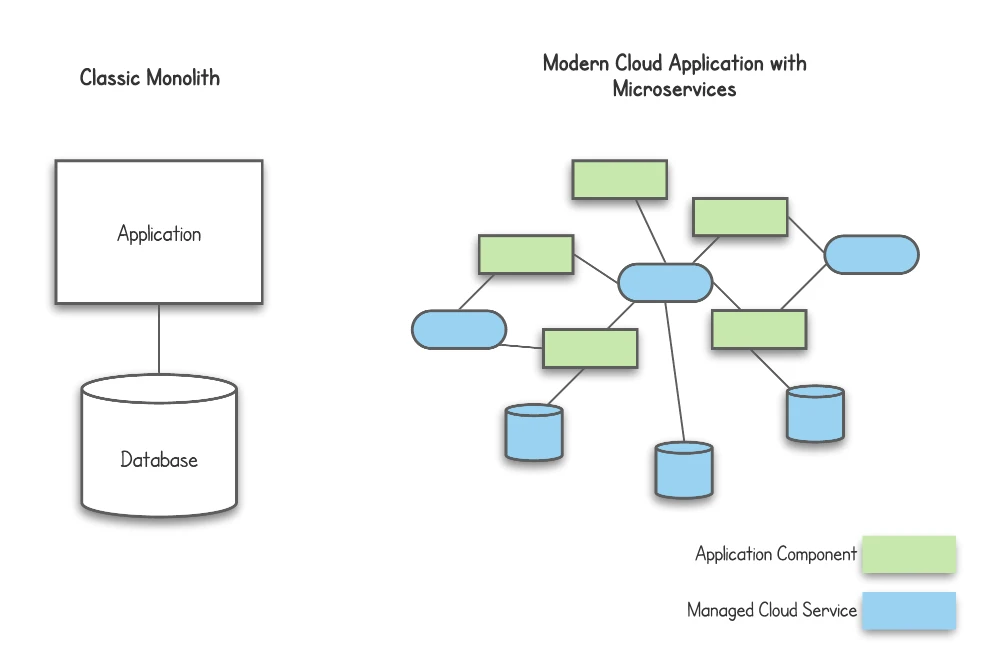
A good understanding of observability applied correctly can give you both a birds-eye view of the system and detailed views on each request. This high-level view helps engineers to visualise the overall structure of the system and know if it is performing well as a whole. To diagnose errors or performance problems, you can also drill down into fine-grained requests as they flow through many components, telling you about the experience of individual users. This includes insight into components that are owned and managed by the cloud provider. It can be built on traditional monitoring, alerts and logging but the key to effective observability is having structured events that can be traced through every component.
So what can you expect from implementing observability in a modern cloud application?
- Know when issues happen and fix them before your users experience any problem.
- Detailed metrics about the technical aspects of your system combined with business metrics. A business metric could be something as simple as the total value of all transactions created in the system. By measuring such metrics, having expected thresholds and triggering alarms, you not only get alerts when an underlying problem occurs, you generate data that facilitates data-driven business and product decisions.
- The total cost of engineering as a proportion of revenue drops as a result of higher application quality, getting teams out of firefighting mode and shipping more valuable product features more frequently.
How to get started with observability
To start putting this idea into practice, there are many options, including those from all cloud providers as well as dedicated, third-party offerings. In terms of third party solutions, Honeycomb, New Relic and Datadog are very powerful examples.
Since fourTheorem is an AWS partner and favours adoption of managed services wherever possible, we have built a lot of powerful observability solutions using services like CloudWatch and X-Ray. These services require a lot of up-front research, configuration and development. This led us to build SLIC Watch, an open source tool to fast-track the setup of these services and get up and running immediately.
Providing good levels of observability can be a challenge for an organisation. But in the age of cloud computing and microservice architectures, observability is something we can’t simply forego. Observability is a necessary investment that will seriously pay off, empowering the organisation with the tools needed to stay on top of cloud deployments while the business focuses on innovation and growth.
Do you have an observability challenge or success story to share? Get in touch and let me know or add your comments below. We would love to hear your take on this topic!

")
