
This post is a write-up on an approach to doing blue/green deployments with serverless AWS resources using Terraform and CodeDeploy. We’ll cover what blue/green deployments are, how to run them, and what changes need to be made to your infrastructure as code and CI pipeline, as well as introduce you to some strategies to ensure that the process is refined and streamlined to make them run smoothly.
Doing blue/green deployments, especially with the modern stack, using different IaC tools, CI and cloud providers along with having many serverless components added into the mix of the architecture is not easy. There will be a lot happening in order to do blue/green deployments in this particular approach and may initially come across as complex. But we think it’ll be worth exploring and learning about this subject to at least get you thinking about safer deployments by providing real-life examples. The approach described in this post has been used in production grade services serving millions of requests and as such, the process has been battle-tested. This post also aims to contribute to the space of serverless based blue/green deployments on AWS since it’s something we feel isn’t very much talked about along with very little content coverage in the community. We also have a sample demo of an ECS based service with blue/green deployments for you to see the inner workings and adapt for your own use cases after understanding the techniques described in this post.
Let’s dive into it.
What are Blue/Green deployments?
Safe Deployments
All of us who have been working in software development and deploy code to production know that one of the most crucial times when you’re most likely to have issues with your services is during or immediately after a deployment. No matter how good your test coverage, QA and pre-production checks are, something can always (and will from time-to-time) go wrong. Whether that’s due to different configurations in different environments, different versions of other dependent services in the environment you’re deploying to, or just due to the higher volume of traffic the services receive, it’s impossible to be 100% confident that the code version you’re deploying will work as intended. It’s also worth mentioning that deployments are rarely instantaneous, so you can wind up with a mix of versions serving live traffic in some cases leading to the other unexpected issues.
Deployment Strategies
Blue/Green deployments try to mitigate this risk by enabling safe deployments, allowing you to deploy the new version of your service stack alongside the existing version. During a deployment, live traffic is still routed to the existing version of your service while you deploy, hydrate and test the new version to ensure it works as expected. Only when there is confidence that the new version is working successfully as intended, you can start routing live traffic to the new version of the service. Once all the traffic has successfully been shifted over to the new version, you can safely tear down the previous version of the service’s stack.
There are also other strategies similar to blue/green like canary which will allow you to deploy a new version of your service and route a small subset of live traffic to it. Provided that the new version works as intended, the live traffic can be shifted incrementally in phases. If things go wrong, the incremental shift control stops moving traffic to the new version and you can rollback to the existing live version of the service. The canary strategy can also take various forms as there is a high level of control based on the percentage of traffic to shift in each phase, amount of time spent in each phase, predicates of moving into the next phase as well as others.
How to orchestrate all of that?
Using AWS CodeDeploy
AWS CodeDeploy has great support for Blue/Green and Canary based deployments. CodeDeploy functions in different forms depending on your application’s compute platform. As well as managing the blue/green transition, CodeDeploy also supports running hooks at various stages of the process, which we’ll discuss shortly. In this post, we will be looking at Lambda and ECS deployments although EC2 instances and on-prem workloads are also supported:
- Lambda – works with aliases, traffic is shifted from one version to a new version of the same Lambda function.
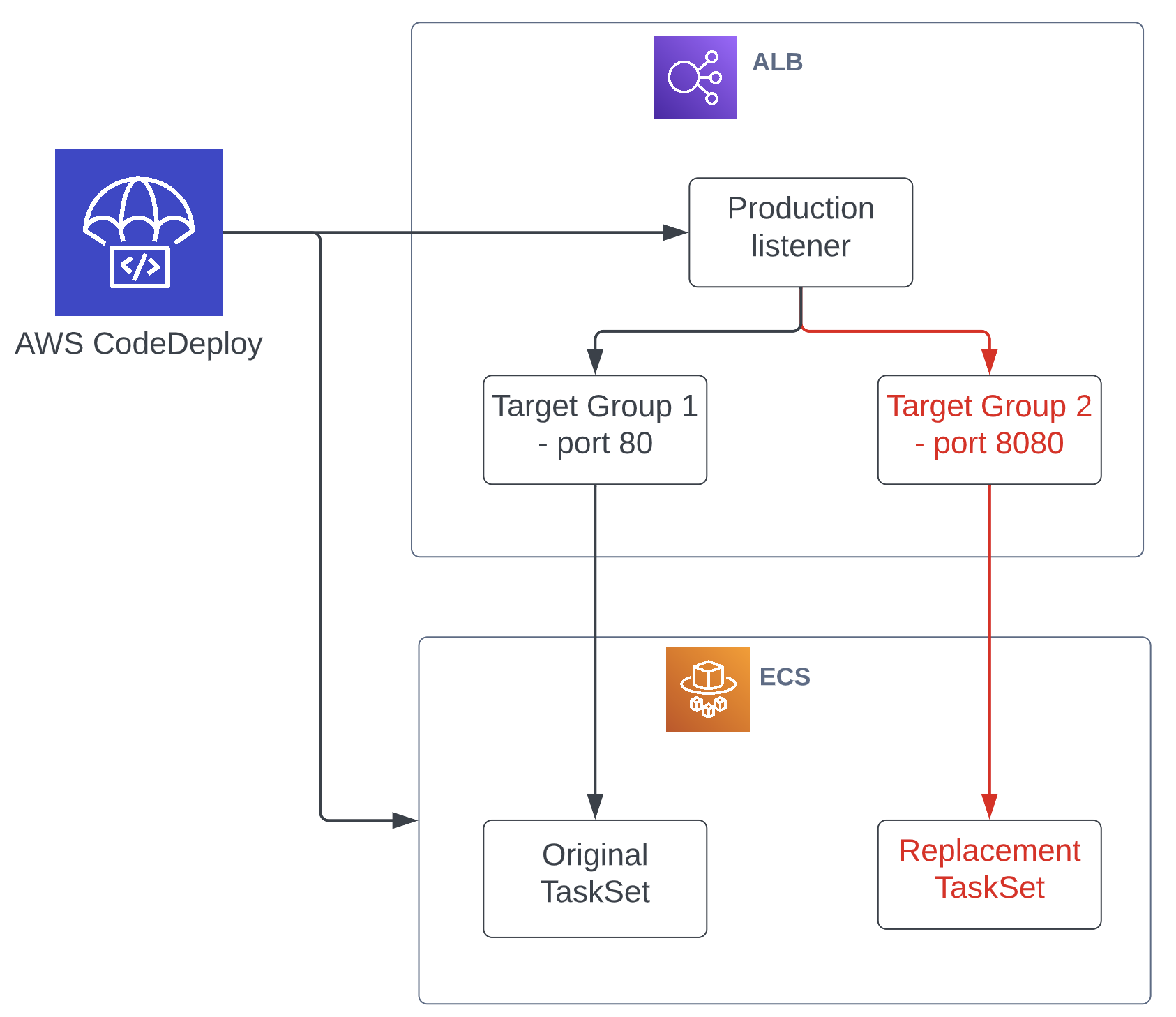
- ECS – Traffic is shifted from a task set to an updated, replacement task set in an ECS service using ALB target groups
For Lambdas, that means versioning your functions, and instead of the Lambda triggering services (SQS, Kinesis, API Gateway etc) being mapped to the main lambda ARN (which points to theLATESTversion), you map them to an alias (liveorprodas the name of the active alias as an example). During a blue/green deployment, CodeDeploy will migrate the version that thelivealias is pointed to from the current one to the new one.
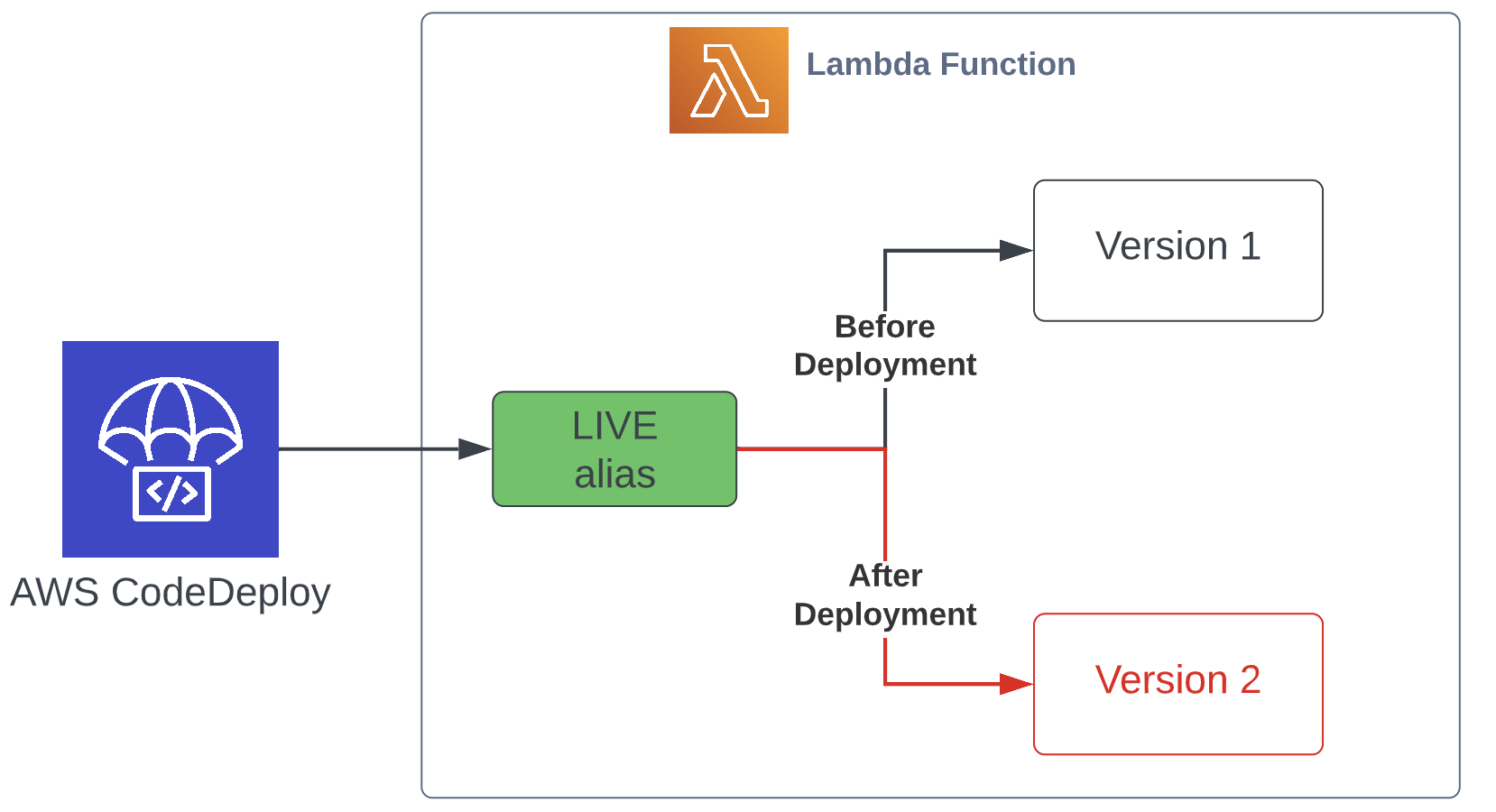
For ECS services, the deployments are performed by manipulating the target groups belonging to an ALB. You create 2 target groups and listeners for your service (rather than 1 that you would usually create for a simple ALB to ECS routing to the active version of your service), both attached to the same ALB but using different ports (80for the existing version and8080for the new version as an example). During a blue/green deployment, CodeDeploy will switch the target groups and listeners around, so that the new version’s target group, which was previously mapped to the8080port, gets attached to the live listener on port80.
Using Terraform
It’s well and good if your service is just a single Lambda or ECS task, but in reality that’s never the case. Most real life applications will also have databases, ingestion pipelines, config and other associated resources, all of which must also have 2 versions that coexist in parallel during a deployment to enable the new version of the service to be validated before the blue/green transition occurs. To achieve this, the Terraform infrastructure code can be configured to have resources setup as pairs – 2 databases, 2 queues, 2 Lambdas etc. Essentially, everything that needs to run side by side is defined as a double pair. This means that when Terraformapplyruns, we have 2 of each the resources – 1 coupled to the existing live service, and the other coupled to the new version of the service we’re going to transition to. When Terraform has finished theapplyoperation and created the resources for the next version, it invokes a Lambda which in turn will prepare and execute a CodeDeploy deployment.
Using CodeDeploy Hooks
CodeDeploy hooks are the essential ingredient to bringing all this together. By design, CodeDeploy hooks are lifecycle operations that are executed at various points of the deployment. For example, you may want to run migrations and seed an empty database or warm up a cache store before the transition and tear down of resources on the dormant stack after the transition has occurred to avoid extra costs.
The following hooks are available for a Lambda deployment:
BeforeAllowTraffic– These run before thelivealias is modified and can be thought as setup stepsAfterAllowTraffic– These run after thelivealias has been modified and can be thought as teardown steps
For an ECS deployment you have a few more hooks available:
BeforeInstall– These run before everything else, specifically before CodeDeploy attempts to run any tasks using the new task definition, this is where you ensure everything is in place for your service to start up, for example preparing a SQL database to receive connectionsAfterInstall– These run after the new tasks are running, but before they’re attached to the non live ALB listener. You can use these for any setup that can run after the task has started up. These can also be used for steps where you might want to run actions that depend on the operations in the BeforeInstall hook, but require the resources to have settled such as seeding or scaling up a database cluster created in BeforeInstall so that it is ready to receive live trafficAfterAllowTestTraffic– These run after your new tasks are connected to the non live listeners on the ALB. This is where you can test the new version of your tasks and service by sending traffic to the associated port and making sure any validation and required data or config is in place, and that the service is healthy and responding as expectedBeforeAllowTraffic– Similar to the AfterAllowTestTraffic hook, these run after your new tasks are connected to the non live listeners on the ALB but before the listeners are swapped and traffic has shifted. You could also perform all or additional validation steps or skip this hook entirelyAfterAllowTraffic– This is the last step which runs after the listeners have been swapped and live traffic is being routed to the new service. This is where you run you can run your teardown operations on the dormant version of the service
Exploring hooks further
The hooks are executed as a Lambda function. For each hook you want to perform some steps in, you define the name of the Lambda function to be invoked. At various stages of the deployment lifecycle, CodeDeploy will invoke the Lambda associated with that hook, passing through the ID of the deployment and a unique token. The Lambda can then perform any steps required and then report a success or a failure status using the token it was passed when invoked.
This can potentially be a problem since no useful data about the deployment is passed to the hook Lambda in the event, so any other metadata about the deployment must be provided through other means. Lambda is able to fetch some general CodeDeploy deployment metadata using the CodeDeploy APIs from the SDK . But there isn’t any way of passing any specific configuration in there. So the simplest way to get data about what operations to perform on what resources is to get Terraform to deploy the hook Lambdas when it runs itsapplyoperation as part of your application and embed the tasks to perform and any other data they require into the Lambda artefact (code, environment variables, IAM permissions etc). The side effect of this though is that you can end up with lots of extra lambdas deployed alongside each service in support of its blue/green deployment pipeline. This can however be solved quite easily if there are common conventions around your services within your team. You could look into using common deployment hook Lambdas which are used by all of your services along with some config store which can be used by these Lambdas during a deployment to share metadata about the deployment. DynamoDB would be an excellent choice for this. It’s also worth mentioning that CodeDeploy deployments have a hard limit of 60 minutes, this means that all of your hooks should have completed within this window.
CodeDeploy and Terraform working together
CodeDeploy’s blue/green features are actually implemented in CloudFormation, so it’s much more challenging to decouple this pairing when using Terraform since there isn’t a way to invoke a CodeDeploy deployment directly using Terraform. Getting CodeDeploy to work with other IaC tools, in particular a “desired state” type of tool like Terraform (more about this can be learnt in the Terraform docs and also “CloudFormation or Terraform?” AWS Bites podcast), is somewhat more involved so let’s see how we can achieve that.
Firstly, we still can use Terraform to create, update and destroy almost all of our resources. However, there are some significant changes required to how you declare resources. Usually, the first public facing entry point into a service is typically an API handler. This is the only component that CodeDeploy is going to manage the process of running 2 instances side by side for the duration of the deployment. All other components of the service like databases and data ingestion resources will need to be managed through other means. That means, you will have 2 instances of the resources like databases, ingest handlers, queues etc. This is straightforward to implement in Terraform usingfor_each functionality on resources. Below is an example of what this looks like for an SQS queue:
The result of the above definition is 2 SQS queues, namedbg-service-queue-a-devandbg-service-queue-b-dev. You can also see how they refer to other associated resources which are also duplicated in the the reference to the DLQ’s ARN above:aws_sqs_queue.ingest_dlq[each.value].arnwhereeach.valueis referencing eitheraorb.
In addition to creating the required duplicated resources, we also need to address the following:
- Stopping Terraform from modifying any live and active resources. For example, if the deployment involves changing the name of a database, and the
aset of resources are currently in live and in use, we only want to modify thebdatabase since that will be associated with the next version of the deployment. - Stopping Terraform from undoing anything that is being managed by CodeDeploy. For example, if we’re using CodeDeploy to modify the
livealias for a Lambda, we wouldn’t want Terraform to update that when theapplyoperation is run, and for an ECS service, we wouldn’t want Terraform to update the container definitions for that service.
To solve problem 1, we can use Terraform’signore_changeslifecycle meta-argument. In the snippet below, there is an example to demonstrate this with a DynamoDB table set to ignore changes:
The effect of settingignore_changesto the special value ofallis that Terraform will only create or destroy the resource, but it won’t modify the table in place. In theafterhooks of our CodeDeploy deployments, we can delete the set of resources associated with the old version of the service (aorb), so when Terraformapplynext runs, it will recreate them with the latest parameters, but more critically , it will not modify the existing version of those resources even if any of the parameters have changed. Additionally, we can use a SSM parameter that can be set in theafterhook of the deployment to determine whether theaorbset of resources is now live and active. Terraform can read that value in using adatasource and use it to decide if the property on a resource should be updated or not. If it shouldn’t be updated, we can read the current value from the remote state or a data source and use that instead of the new value.
To solve problem 2, again we can make use ofignore_changesbut this time on the specific parameter, that will be managed by CodeDeploy hooks instead, for example ignoring the container definition changes on an ECS task:
Glueing together CI, Terraform and CodeDeploy
Now that we can have Terraform and CodeDeploy set up in a way to not conflict with each other, we now need to orchestrate running one after the other. Initiating a CodeDeploy deployment involves creating anappSpecconfig that defines the resource to update along with what hooks to run, then calling thecreateDeploymentAPI with theappSpecpassed in. This action can be performed using a Lambda, invoked through a CloudFormation stack with a custom Lambda resource. The CloudFormation stack can reside in the Terraform code itself as a resource and should depend on every other Terraform resource to ensure it’s the very last thing that should be applied. Any metadata required for setting up the CodeDeploy deployment can be passed to this Lambda via Terraform and the CloudFormation stack’s custom resource properties. The Lambda can then create the deployment by having it invoked as part of the CloudFormation stack update. The effect of this is that as theapplyoperation is completing on the Terraform front, a new deployment is created in CodeDeploy which immediately starts running.
There is another gotcha to watch out for here however. While the Terraformapplyoperation is running, Terraform will lock its remote state to stop other deployments occurring at the same time as a safety mechanism to avoid infrastructure corruption. However, since we are doing blue/green deployments, the deployment hasn’t completed when Terraform completes, there is now a CodeDeploy deployment running along with the hooks to perform all the setup and teardown hooks. This means that another CI deployment can be initiated behind the current one, which would start the Terraformplanandapplyoperations while CodeDeploy may still be running and the hooks are still modifying or deleting resources. This can result in your service ending up in a completely broken state, which is obviously not the intention. To prevent this, there are several strategies:
- Concurrency control in CI – ensure that your workflows only ever allow for one deployment pipeline to run at any point in time. This can be achieved quite easily using GitHub Actions’s concurrency control as an example. This control should be used with a waiting script as suggested in the next strategy
- Script based manual terraform locks – have a simple script that is executed as a step in your CI pipeline after both Terraform has finished the
applyoperation and the CodeDeploy deployment has completed to lock and unlock the state lock respectively - Script based CodeDeploy wait – a simple script that runs after the
applyoperation and will poll the status of the CodeDeploy deployment until it either succeeds or fails. The CodeDeploy deployment ID can quite easily be retrieved from the CloudFormation stack’s output value which can be set by the deployment Lambda. If the CodeDeploy deployment fails, the script can exit with a non-0 exit code causing the pipeline to fail null_resource– use this resource within Terraform so that waiting for CodeDeploy is also done as part of theapplyoperation
Using these strategies together in the deployment pipeline can allow for safe and non-overlapping deployments. It also stops the pipeline from showing as complete when the CodeDeploy job is still running. Since the pipeline can now account for both Terraform and CodeDeploy status checks, the overall deployment success/failure can be correctly displayed in CI.
Hooks and Operations on a production-like demo service
Everything we have talked about so far has been quite focused on how to get these tools to work well together. But to really give you an idea of what is actually going to happen during a deployment, it helps to look at some production-like examples. We’ll describe the flow for 2 services, one an ECS Fargate based API backed by an RDS cluster and ingestion Lambdas, the other a Lambda based API backed by DynamoDB and ingestion Lambdas.
bg-demo-ecs-service
This service has an API running as an ECS Fargate service fronted by an ALB, reading data from an RDS cluster which is seeded by an ingestor Lambda. A single running instance of the service looks like this:

Since we need to run side by side during a blue/green deployment, the resources created by Terraform after anapplywill look more like this:
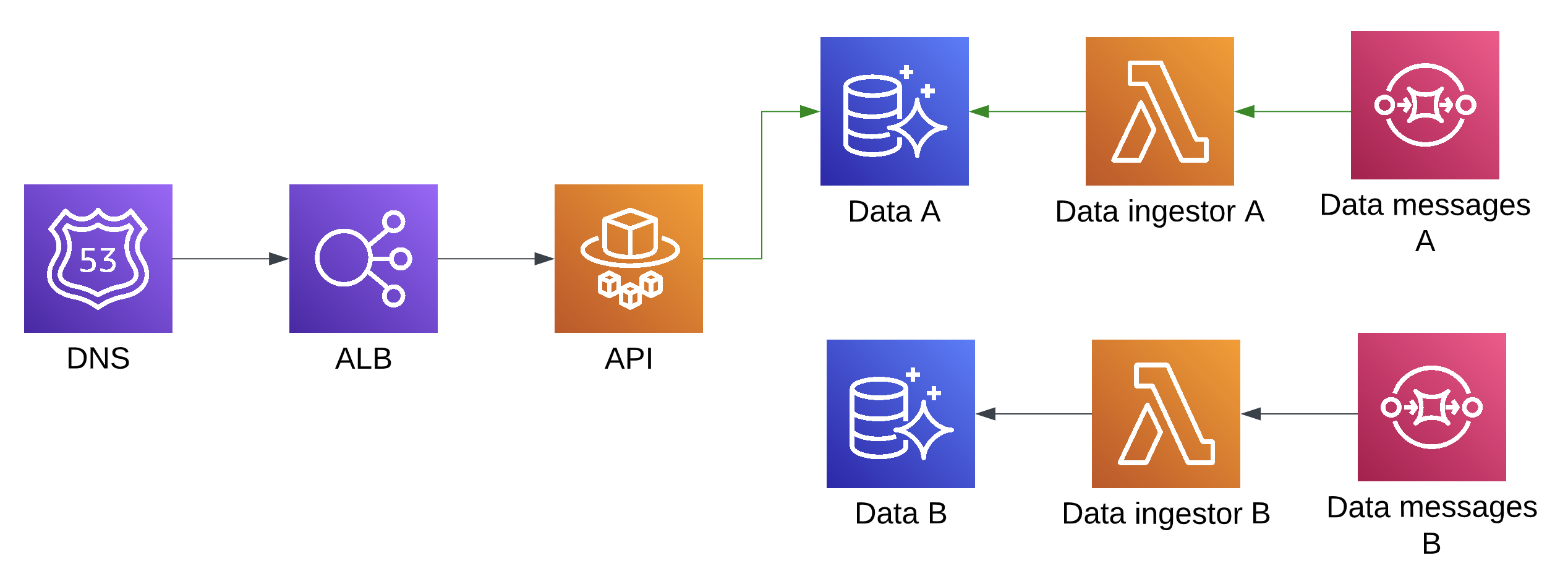
During the deployment process, CodeDeploy will start up another ECS API TaskSet which reads from the Catalogue B database, attach it to another listener on the load balancer and move the traffic over from the older version to the new version. To complete the deployment, numerous other steps must be carried out by the CodeDeploy lifecycle hooks.
Prepare new version
- The replacement database cluster is created by Terraform during the Terraform
applyoperation - Autoscaling minimum capacity on the new database cluster is set to match the current capacity of the live cluster by the
BeforeInstallhook, this ensures that when production traffic hits the new stack, the database cluster is warmed up and there is enough capacity to handle the present load - Replacement database is initialised by running schema migrations in the
BeforeInstallhook - Data sources such as EventBridge rules or SNS subscriptions which feed the SQS data messages queue are enabled for the replacement queue in the
BeforeInstallhook - SQS event source mapping to the data investor Lambda is enabled for the replacement queue in the
BeforeInstallhook - A new task set is created in the ECS service, and is bound to replacement stack’s database, CodeDeploy creates this task set by being provided a task definition containing environment variables for the replacement set’s version resources
- An
AfterInstallhook sends a message to an upstream system to trigger the new version’s data ingestor Lambda to seed the complete dataset required for the service - The new task set is placed in a testing target group which is attached to a testing port on the load balancer by CodeDeploy
Test and shift traffic to new version
- Validation and automated test steps are performed against the replacement version of the service using the testing port by the
AfterAllowTestTraffichook. These steps can include sending traffic to ensure the service is responding. For really advanced checks, you can scrape a sample of the live requests logs, and replay them against the live and replacement versions of your service to ensure the responses match fully or to a specific threshold. This process can be retried multiple times whilst the ingestion process takes place and the database is seeded since it’s likely the first few runs will always fail. To go even further, if you have semantic versioning of your service in place, you can even conditionally bake in scenarios to ignore breaking changes of responses as an example. The possibilities are endless since you are able to perform any customised validation inside the Lambda. All CodeDeploy cares about is that the hook either succeeds or fails. - The replacement stack becomes the live and active receiving traffic on the primary port. What was the live stack is now the old stack and CodeDeploy manages this by swapping the live ALB listener on the primary port
80
Teardown and deactivate old version
- Autoscaling the minimum capacity on the active set is reverted to the normal value in the
AfterAllowTraffichook, and the database will now scale in when traffic lower - Data sources subscriptions like EventBridge rules and SNS subscriptions are disabled for the old stack in the
AfterAllowTraffichook so that the old data messages SQS queue is no longer being used - The SQS event source mapping on the data ingestor Lambda is disabled by the
AfterAllowTraffichook. This will be enabled by Terraform on the next deployment to achieve the desired state. - The old database cluster is deleted in the
AfterAllowTraffichook - The old SQS queue is purged of any messages in the
AfterAllowTraffichook ready for use in the next deployment - The old ECS task set is destroyed by CodeDeploy
The majority of the operations are carried out by the hooks, with CodeDeploy mostly acting as an orchestrator to shift traffic and trigger the hooks at various points in the deployment lifecycle to manage all these operations. Since this is an ECS deployment, we have a lot of choice of hooks to use, and use 4 of them in this example.
There is also a sample demo service we have put together to showcase how a simple ECS based service backed by DynamoDB and data ingestors looks like as code – https://github.com/fourTheorem/bg-tf-ecs-demo – complete with Terraform resource pairs, custom CloudFormation stacks to invoke a CodeDeploy deployment, CI and hooks.
bg-demo-lambda-service
This service has an API running as a Lambda fronted by v2 HTTP API Gateway and backed by DynamoDB tables for holding service and config data which is ingested by Lambdas using SQS and Kinesis:
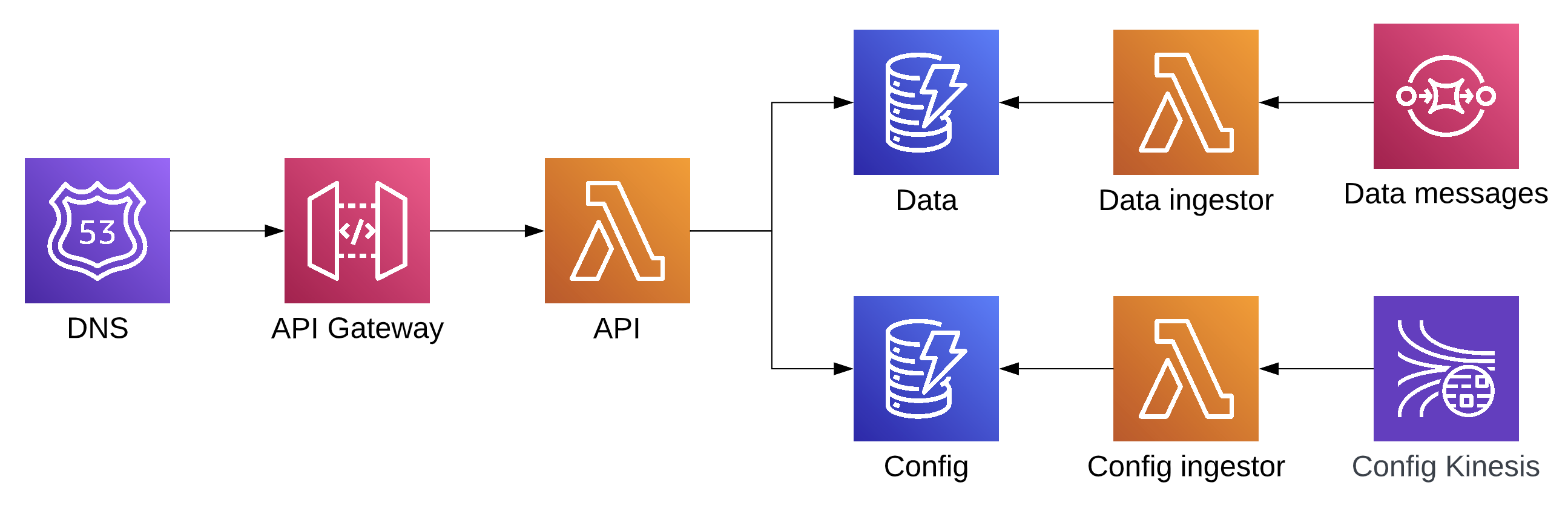
The resources created by Terraform after anapplywill look like this:
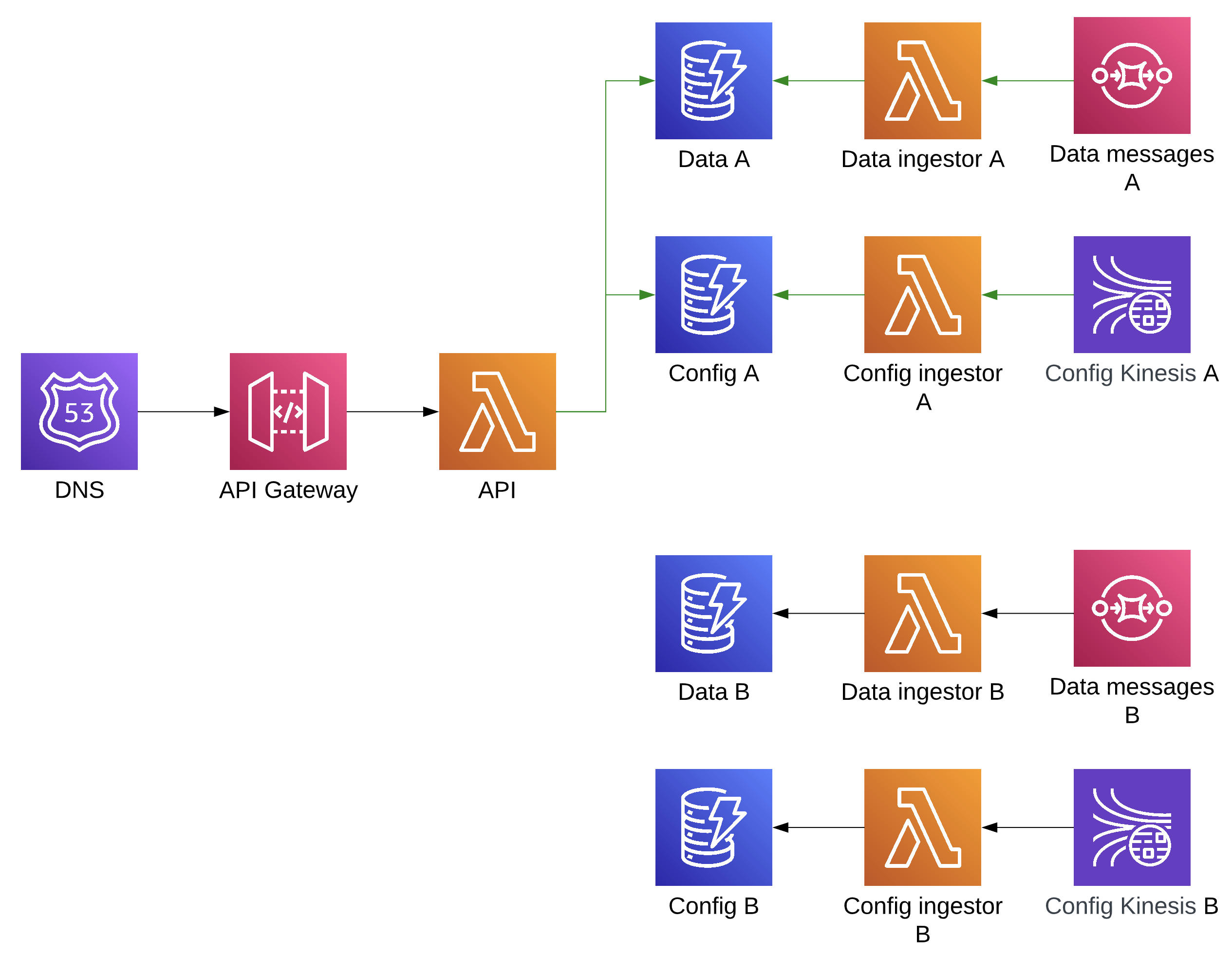
As this is a Lambda target for a CodeDeploy deployment, CodeDeploy is going to be manipulating Lambda aliases instead of ECS task sets and target groups. Sending any validation test traffic to the new version service is going to involve pointing a new API Gateway stage at the new version, whilst thelivestage will always point to thelivealias. The following steps will occur during the deployment:
Prepare new version
- DynamoDB tables are created for the new version of the service along with deployment and new tag versions of the ingestor Lambdas, SNS/SQS subscriptions and event source mappings by Terraform
- The
BeforeAllowTraffichook sends a message to an upstream system to trigger the new version’s data ingestor Lambda to seed the complete dataset required for the service. - The similar can be done for Kinesis config source or, alternatively no actions are required for the config ingestor since the stream will have data retained by ensuring it has the full dataset being added at least once before the retention period of the stream expires. When the event source mapping is created on each deployment, you can simply use
TRIM_HORIZONas the starting position and ingest data in an idempotent manner. A word of caution, this only works if the service is able to ingest that data at a relatively quick speed since there may be huge amounts of data retained in the stream.
Test and shift traffic to new version
- The
BeforeAllowTraffichook starts to perform validation steps on the new version of the service. Again, similar to ECS, you can get quite advanced here by scraping a sample of request logs and replaying them against both versions of the service and ensuring responses match. With API Gateway specifically, you can associate theliveandnextstages each with an API Gateway endpoint which can then be used by the hook as endpoints to distinguish the 2 versions of the service when sending test traffic. - CodeDeploy modifies the
livealias of the API Lambda to point to the new Lambda version of the API handler, which routes all prod traffic to the new version. Since this service uses DynamoDB on demand billing mode, capacity shouldn’t be a major concern, especially if the service is ultimately frontend by a CloudFront distribution. However, if provisioned throughput was being used, there would have to be some mechanism in place in the hook to match the present throughput if the table is autoscaled.
Teardown and deactivate old version
- The
AfterAllowTraffichook deletes the old dynamo tables - The
AfterAllowTrafficdisables the old SNS/SQS subscriptions and deletes the associated event source mapping on the data ingestor Lambda - The
AfterAllowTrafficdeletes Kinesis event source mapping on the old config ingestor Lambda - The old SQS queue is purged of any messages in the
AfterAllowTraffichook ready for use in the next deployment - The
AfterAllowTrafficupdates the active version stored in the SSM parameter toaorbdependent on what version just became active
There are only 2 hooks available for Lambda based CodeDeploy deployments, and as a result, the setup hook is going to be doing a lot of tasks. The hooks have retry mechanisms baked in to ensure the Lambda can reinvoke itself manually if timeout limits are approaching and other sensible defaults.
Wrapping up
Hopefully, this post has inspired you to start thinking about blue/green deployments with your own serverless based AWS services. It’s worth emphasising that this is just one approach to deployments using this strategy and certainly not the standard by any means. We expect more refined tooling and services offered by AWS in the future to help developers to build their suite of deployment tools and promote these types of deployment strategies. An example of this is the recent announcement of fully managed blue/green for Amazon RDS which we believe is a step in the right direction but still doesn’t solve the problem for all other resources belonging to an application’s stack.
There is a good deal of gaps and assumptions in this post that may not apply to your own services, but it’s certainly a great starting point to performing safe deployments and reducing the risk of things going wrong. We are confident in this approach as it has been tried and tested in production environments over many years on mission critical services. If you too want to start implementing blue/green as a deployment strategy, do take a look at the sample demo repository at https://github.com/fourTheorem/bg-tf-ecs-demo. This is an example of an ECS based service with blue/green deployment and includes all of the techniques related to CodeDeploy with ECS services that have been stated in this post.
Finally, if you need help with your AWS projects, don’t hesitate to reach out to us, we’d love to help!


")