


Hosted by Peter Elger and Keelin Murphy
This month we were delighted to have Professor Paul Walsh from CIT speaking at Cork AI. The talk introduced support vector machines (SVMs), which are supervised machine learning algorithms that are widely used for a range of real word problems. Key terms and concepts were described, showing how SVM algorithms can build linear and more complex models that accurately classify unseen data. In order to get the best machine learning performance, the tuning and evaluation of SVMs was also demonstrated. Live demos and hands-on coding opportunities were provided, and a real-world application was showcased.
For the hands-on portion we used R, an open-source programming language and environment for statistical computing and graphics (https://www.r-project.org/), along with JavaScript.
About Paul Walsh
Prof. Paul Walsh has a PhD in Computer Science. He is a director of the SIGMA research group which is based at Cork Institute of Technology. SIGMA focuses on applying machine learning to real-world problems, and Paul has a keen interest in solving problems in health-care and life science. He is an experienced machine learning technology expert having published over 80 articles & book chapters on the subject.
Paul has consulted with industry on the topic of machine learning, and has founded several start-ups, including life science software company nSilico, which uses machine learning to analyze genomic and biomedical data. He is the principal investigator for major national and international research programs, including SFI and H2020, and is a certified technology and project management professional with experience in consultancy for major international clients

So what is a Support Vector Machine?
A Support Vector Machine (SVM) is a supervised machine learning algorithm that can be employed for both classification and regression purposes. SVMs are more commonly used in classification problems and are based on the concept of finding a hyperplane that best divides a data set into two classes. Support vectors are the data points nearest to the hyperplane; the points of a data set that, if removed, would alter the position of the dividing hyperplane. Because of this, they can be considered the critical elements of a data set.
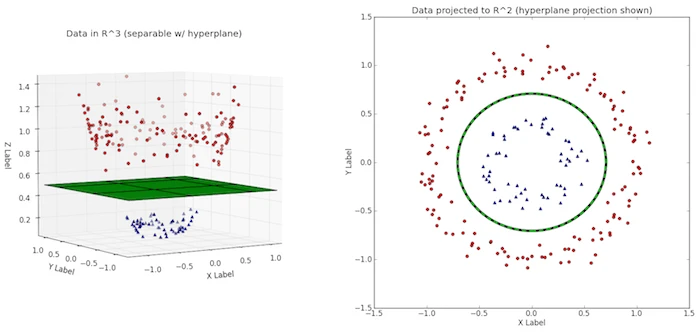
When there is no clear hyperplane it is difficult to divide a dataset into two classes. This is where the Kernel Trick comes into play by adding an extra dimension, like in the image below, you can then more easily identify a hyperplane.
To learn more check out our video of the session below.
To share your thoughts, or to speak to a member of the fourTheorem team, get in touch today.