

In this post, we are going to walk through a demo of creating a simple serverless API using the new visual development tool AWS Application Composer. We’ll discuss what the tool is, explore how it works, describe a target use case to implement and finally share some thoughts on the developer experience having used this new offering from AWS.
Overview of Application Composer
Launched at re:invent 2022 and recently gaining GA status, AWS Application Composer is a new development tool that allows you to build serverless applications with ease. The tool provides an canvas-like interface for visually composing serverless applications using limited but popular resources like Lambda, API Gateway, SQS, Dynamo and Kinesis Data Streams. It’s intended for developers who are building applications in AWS using common integration patterns and want to start off with boilerplate code. They may have not used serverless before or know where to start or how best to make them work together, and so the tool aims to simplify and accelerate the architecting, configuring, and building of serverless applications.
It can also be used for ancillary purposes like:
- Rapidly building POCs and prototypes of serverless applications
- Collaboration and review of existing serverless projects
- Generating architecture diagrams for project documentation
- Helping with onboarding new team members to a project
- Using best practice blueprints defined by AWS
The code generated is only compatible with the AWS SAM framework at present. A template.yaml file is created with SAM and CloudFormation resources along with basic Lambda handler files based on the runtime of choice.
One of the key benefits of AWS Application Composer is its ability to create APIs quickly and easily. They can be created using a drag-and-drop interface and outputs the necessary code to be able to deploy it. In the next section, let’s build an API using Application Compose to see this in action.
Test driving Application Composer
An example use case
In this section of the post, we’ll take on the role of a single developer who has been tasked with creating a new prototype of an API service that will respond with motivational quotes for a wellbeing mobile application. It can be assumed that the developer has basic AWS and cloud knowledge, but hasn’t necessarily worked with many serverless resources.
Below are the requirements for the API service:
- The API response should be in a JSON format and return the latest quote and its ingested time from the data store
- The endpoint path should be /get-latest-quote
- The endpoint should accept GET requests only
- All quotes should be stored in a data store
- The quotes will be provided for ingestion by a third party service, however, for now, they can be mocked through a static list
With the above in mind, we need to decide what resources we need. These can be the following.
- API Gateway – most commonly used data-plane entry point for API calls that represent client requests to target applications and services
- Lambda – we know there will be some code involved as we’ll have to read and write data. We could also use Lambda function URLs for the API
- DynamoDB – a simple and fast NoSQL data store, perfect for storing a simple quote items
- CloudWatch/EventBridge Scheduled Events – since we need a way to to mock ingestion of quotes using some background process, a simple scheduled task that runs every minute can be used to simulate data updates. In the future when we are ready to integrate with the real integration, there will be minimal code changes involved and the mock approach can be easily replaced
The target architecture for our point of reference should be something along the lines of the following.
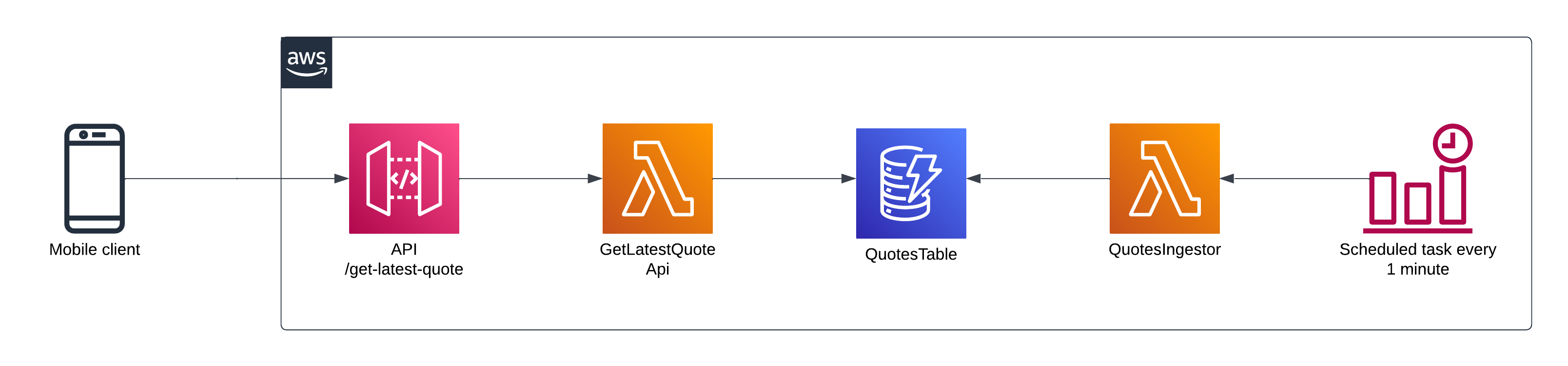
The API response body can be structured as the following.
{ "quote": "<string>", "ingestTime": "<string>" }
Creating the API in the Application Composer canvas
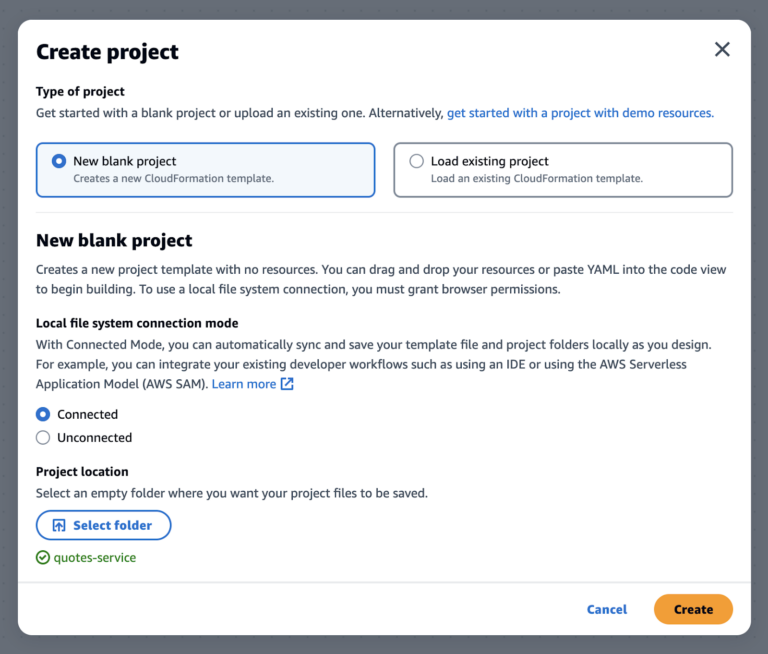
From the AWS Application Composer page console, we can create a new project from scratch for our API service. Once selected, there are 2 composer mode options to choose from:
- Connected – your local workspace (a folder) is connected to the cloud workspace, so any changes you make from either the canvas or template.yaml code in an editor will automatically sync at both places. NOTE: Only some browsers with File System Access API support are compatible like Chrome
- Unconnected – when designing in unconnected mode, only an application template file is generated and can be manually exported
To fully experience Application Composer, we choose the Connected mode. A new empty folder must be provided in this mode to link the design canvas and the local filesystem.
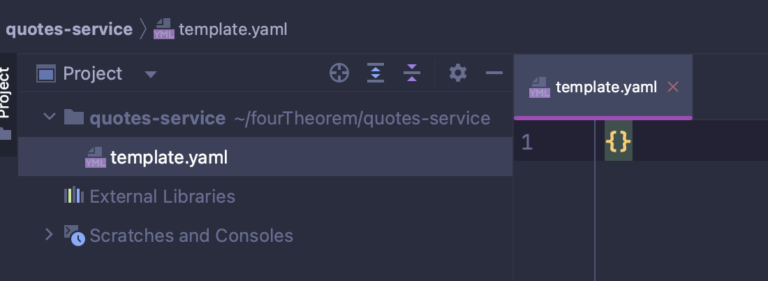
After creation, an empty template.yaml is also created in the folder.
We are now ready to build our service from the canvas. To begin with, we start off with an API Gateway resource:
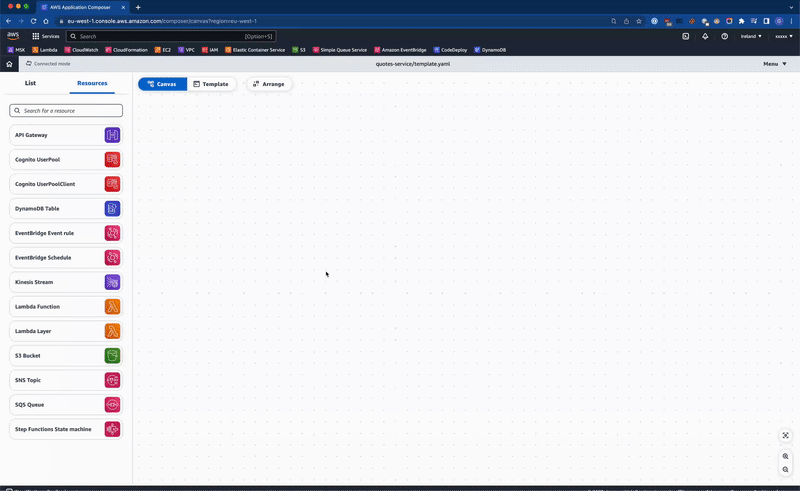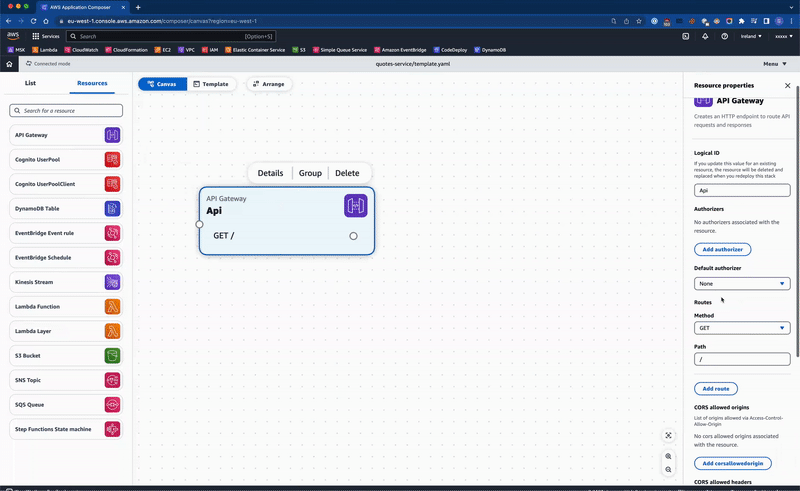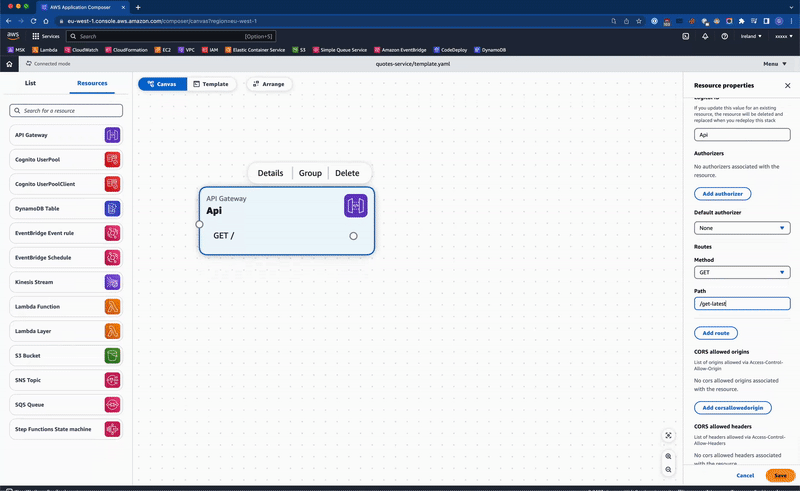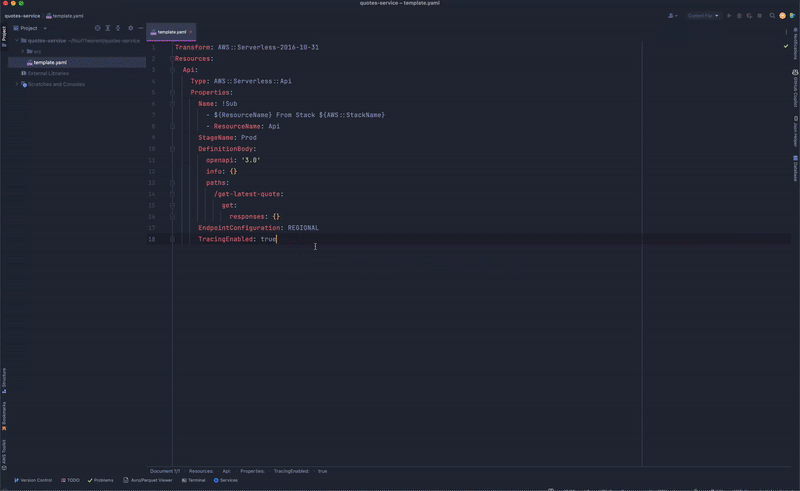
By dragging the API Gateway resource from the list onto the canvas, the template.yaml file is updated with the CloudFormation resource. There are limited options to name the resource, define the endpoints and optionally add any authorizers.
We then add the Lambda handler resource, choosing the nodejs.18x (typescript) runtime and adjusting memory and timeout settings.
The API Gateway and Lambda resources can now be linked together by dragging the link line from the white join dots.
Back in our local workspace, the template.yaml file is updated with the associated CloudFormation resource. All necessary permissions and log groups are also created.
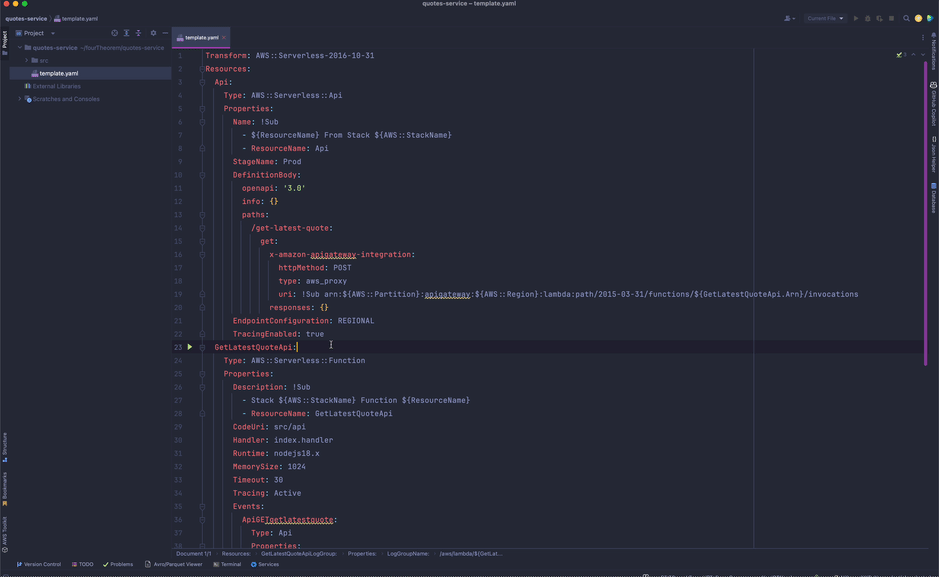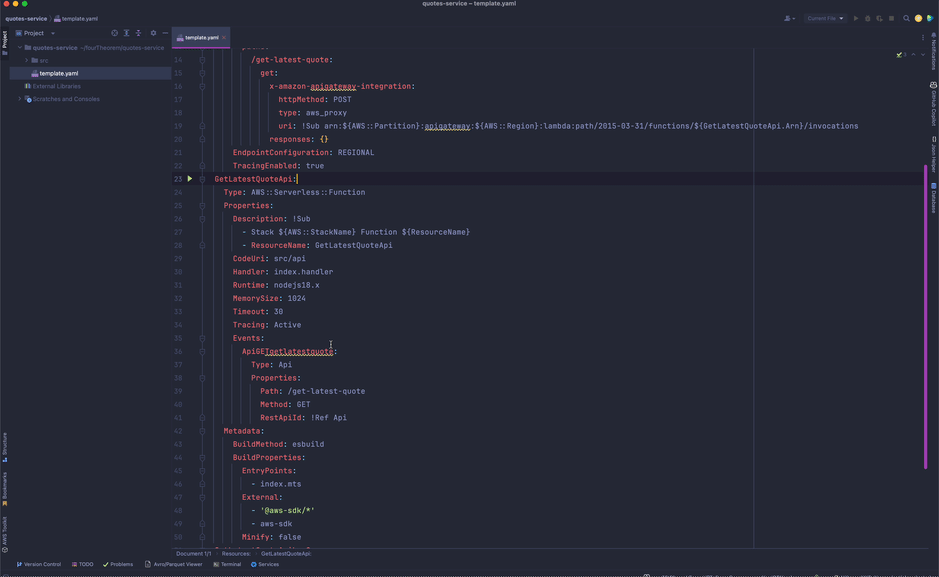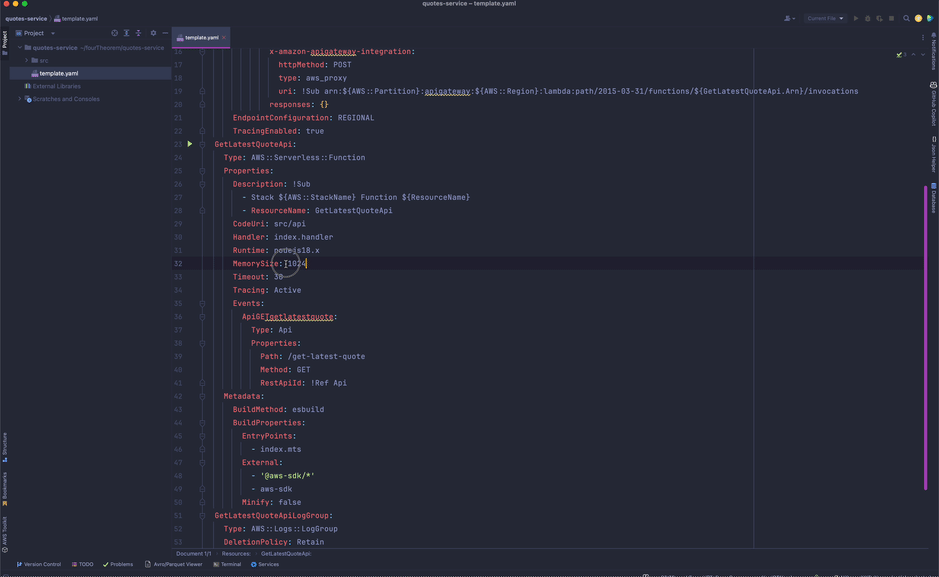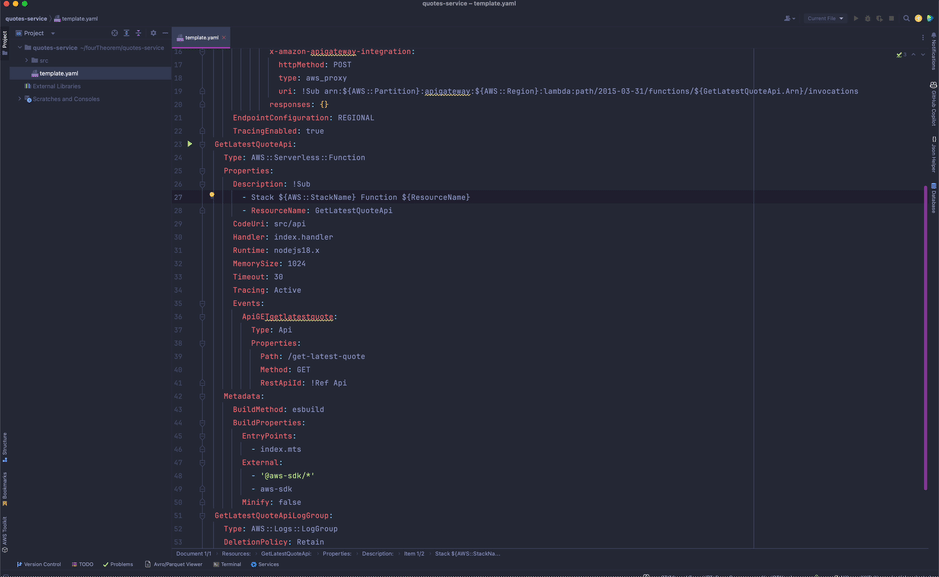
A Lambda handler file for the API where our code to respond to the incoming requests will reside has also been created. It contains an empty handler function where we are expected to write the implementation code for what we want to do.
// ./src/api/index.mts
import { Handler } from "aws-lambda";
export const handler: Handler<object, object> = async event => {
// Log the event argument for debugging and for use in local development.
console.log(JSON.stringify(event, undefined, 2));
return {};
};One by one, we add all of the resources for the service and our canvas now looks like this:
We’ve now added all of the resources and are ready to write the supporting code in our handlers. Our endpoint will be created by API Gateway, and when hit, will invoke our GetLatestQuotesApi Lambda handler. The handler will then query the DynamoDB table for the latest quote.
export const handler: Handler<APIGatewayEvent, Response> = async event => {
console.log(JSON.stringify(event));
try {
// query the dynamodb table for the latest quote
const params: QueryCommandInput = {
TableName: process.env.TABLE_NAME,
KeyConditionExpression: "PK = :pk",
ExpressionAttributeValues: {
":pk": "QUOTES#ALL",
},
ScanIndexForward: false,
Limit: 1,
}
const {Items, Count} = await dynamo.send(new QueryCommand(params));
if (Count === 0) {
return {
statusCode: 404,
body: JSON.stringify({message: 'No quotes found'})
};
}
const {quote, SK} = Items[0];
const ingestTime = SK.split('#')[1];
return {
statusCode: 200,
body: JSON.stringify({quote, ingestTime}),
};
} catch (e) {
console.error(e);
return {
statusCode: 500,
body: JSON.stringify({message: 'Something went wrong, please try again later...'})
};
}
};For DynamoDB, we’ve chosen a relatively simple key structure which will use a partition and sort key. We also use a TTL expiration key to flush out outdated quotes since we only have one access pattern in our API which is to only return the latest quote.
The ingestor Lambda will be invoked every minute by an EventBridge schedule resource which will put a random quote chosen from a static list into the DynamoDB table.
export const handler: Handler<ScheduledEvent, void> = async event => {
console.log(JSON.stringify(event));
// put a random quote into the dynamodb table
const quote = getRandomQuote();
const params: PutCommandInput = {
TableName: process.env.TABLE_NAME,
Item: {
PK: 'QUOTES#ALL',
SK: `INGESTED#${Date.now()}`,
uuid: randomUUID(),
quote,
expiration: (Date.now() / 1000) + 3600, // 1 hour from now
}
}
console.log(JSON.stringify({message: 'Saving item with random quote to dynamo', params}));
await dynamo.send(new PutCommand(params));
};All of the necessary IAM permissions will also be created automatically using common policies and action. This however may need fine-tuning since the canvas cannot predict exactly what actions may be required for the interaction between resources – for example Lambda to DynamoDB permissions use CRUD level access which may be too open for the API handler since that only needs to read data.
The Lambda handler code we’ve implemented can be viewed in the GitHub repository for this example demo – https://github.com/fourTheorem/application-composer-quotes-api-demo. The final template.yml is now complete with all of the resources we require for our service and ready to be deployed.
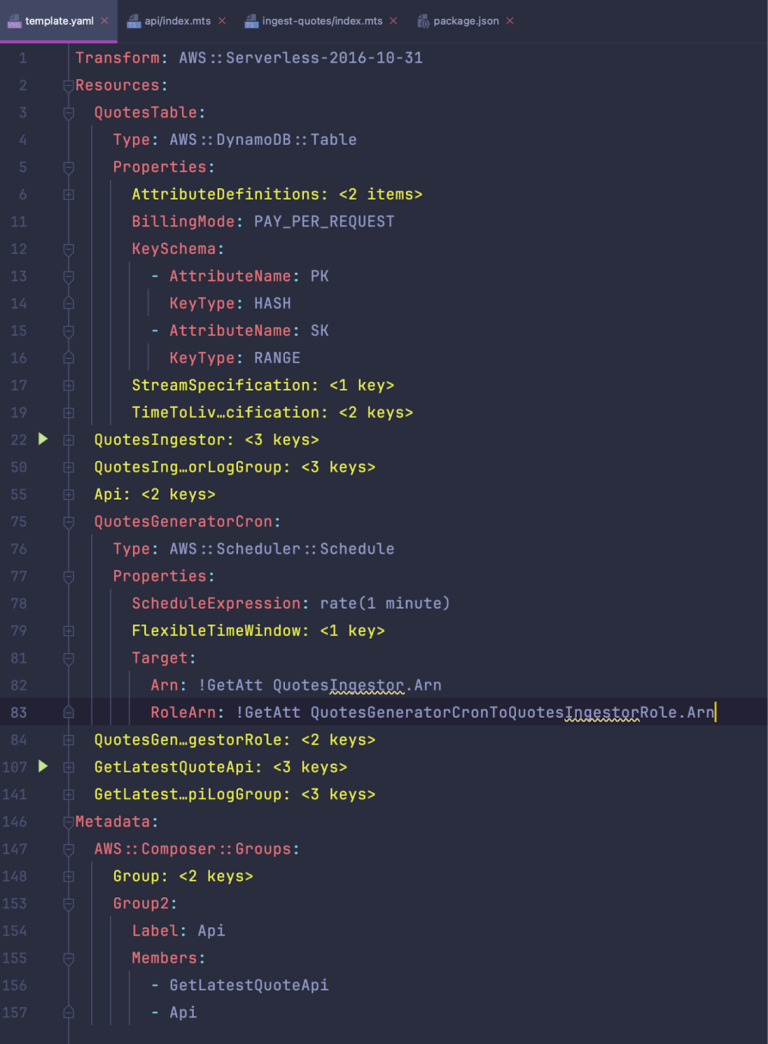
Deploying the API service
Now that we have generated our infrastructure as code and completed the Lambda handler implementation, we can go ahead and deploy the API service using AWS SAM. Ensuring that we have the SAM CLI installed, the relevant AWS credentials configured and installed all code dependencies, we can run the following commands in the root of the repository to deploy this service in AWS:
$ sam build
$ sam deploy --guidedSAM will build our project by compiling our Lambda source files and creating artefacts and then synthesize the CloudFormation template from the template.yaml file. It will then initiate the deployment in CloudFormation and stand up the complete stack.
The API endpoint URL can be viewed from the Lambda handler page in the console. Having a stack output of the endpoint would have been useful as default behaviour when the template is generated with API Gateway and Lambda resources, but this can be handled for convenience later on. When we send a GET request to the endpoint, the API successfully returns the latest quote along with the time it was ingested into the DynamoDB table.
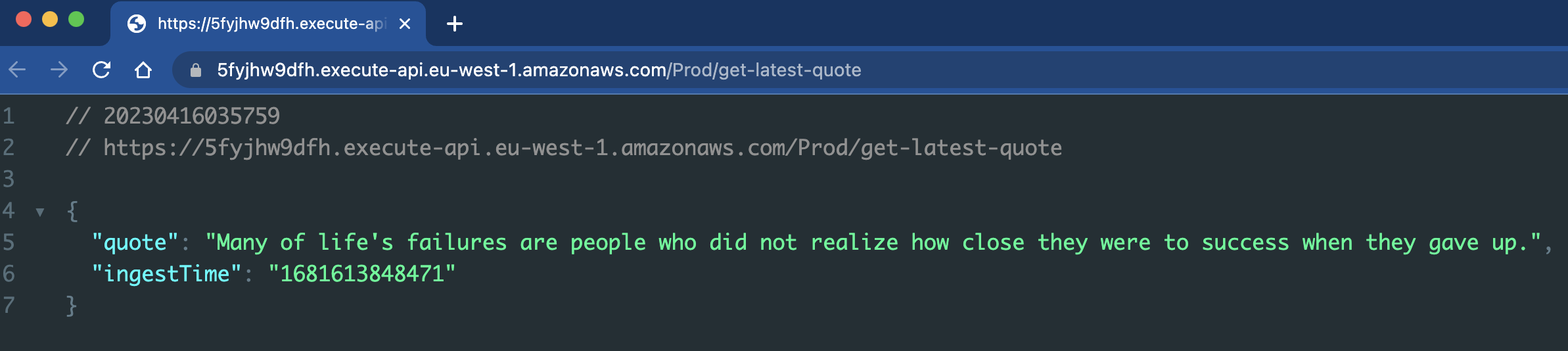
Thoughts on the developer experience
It’s clear that AWS Application Composer’s target audience, in large, are those that are new to AWS and serverless-based architectures. After using the new offering, we observed the following as part of the experience building the quotes API service.
Strengths
- The drag and drop functionality is the star of this tool. You don’t need to write any code to get started with when creating your application service from scratch. The canvas makes it easy to add, remove and modify any supported resource and visualise your application before deployment. This provides confidence at the beginning, however, as the application grows in the future with the addition of resources not supported by Application Composer, the full picture of your architecture will not be complete.
- The template generated with the associated resources once they are placed in the canvas follows best practices so users don’t need to be too familiar with serverless and CloudFormation to get started quickly.
- The grouping feature is quite useful within the canvas to logically separate various parts of the service, for example API and Ingestion. This helps to quickly establish the context of resources which is beneficial for more complex apps with a larger number of resources.
- Developers need to be aware of the IAM permissions and policies that are used by default for resources. The defaults are a good starting point but, depending on the behaviour of the resource, some actions within the policies can be considered insecure.
- For other defaults which can be more predictable, a really nice touch that is worth calling out is that Application Composer creates some basic environment variables references for Lambda resources based on the resource that Lambda function is linked to. For instance, the name of the DynamoDB table is automatically set as an environment variable which is required when reading and writing data.
Weaknesses and areas of improvements
- For Lambda resources, when you first create the resource in the canvas, default names are assigned automatically. As the associated handler code files are also generated, the folder which contains the Lambda handler code gets created with this name. If we update the name in the canvas, the local folder name in the file system is not updated, but rather a new folder with the updated name is created. This is quite confusing at first, especially when you’re going back and forth with naming updates. You’re also left with the responsibility of cleaning up these obsolete folders. We assume this is intentional behaviour to avoid accidentally losing files without intent – especially since there is no source control to begin with. Perhaps explaining the behaviour somewhere in the canvas options would be useful as this had to be figured out with several tries.
- Any resource type that you may need in your service which is not supported by Application Composer will have to be defined yourself in the template.yaml. As such, it’s very likely that some degree of customisation will be required for real-life applications which typically involve some levels of access to VPCs, cross account permissions and various databases all with countless configurations
- If we want to use monorepos or organise the folder structure and contents of the Lambda handlers to your own conventions, again, this will be up to us. Application Composer exports all files using its own internal conventions – these are relatively basic and limited so adding any changes on top are trivial enough. On the other hand however, as the application starts to mature with more features and additional handlers are required, so do the developers who become familiar with SAM. It is likely that once the user has grasped the concepts of their application, they may not even require using Application Composer to create additional resources since they have real working references already. This then makes it easier to maintain consistent file structures.
- It’s very common to import information about resources created using different IaC stacks, for example – VPC and subnet IDs. Again, it’s up to the user to define this in the template.yaml. This might be considered an advanced use case as it can be argued that the user is aware of such constructs and is able to create and manage applications without needing to use Application Composer
- There aren’t any options to create CloudWatch alarms for the different types of resources. This would help folks with adoption of observability best practises early on when starting out with their applications. We don’t expect complex alarm scenarios here but even just basic monitoring for error related metrics would be useful to provoke thought for the user.
- The user requires knowledge of AWS SAM in order to deploy. There isn’t any way to automatically deploy from the canvas so it’s up to the user to take the generated template and get it deployed using SAM.
- From time to time, the canvas stopped responding and syncing back to the local workspace. This happened multiple times and was quite frustrating as the only way to recover was to reload the browser web page and open and load the project from your local workspace again. This also meant that any changes being done during the unresponsive period had to be reapplied – if we hadn’t forgotten about them!
Conclusion
AWS Application Composer is a neat addition in the serverless ecosystem to simplify the process of creating, and updating serverless applications on AWS. From our experience, it’s primarily intended for newcomers in AWS but can also be used for quickly standing up prototypes (we’re thinking about hackathons where time matters!).
The tool generates all infrastructure as code including skeleton Lambda handlers that follow best practices, making it a great choice for developers who want to rapidly create serverless applications. Another thing that we like is that you can use it to create different types of architectures other than the traditional API and synchronous. Event driven architectures are now easy to create – just link a Lambda and a S3 bucket together for S3 notifications, or link a DynamoDB table to Lambda to enable streams to process items modifications in the table – all without having to think about the event source mappings and other glue involved in between the resources. By having the power to compose different services together in a visual manner, new users can truly get up to speed with unlocking what is possible and start delivering value sooner.
Overall, the tool is a step in the right direction and really useful for some, but we’d like to see the tool evolve in the future to cater for more complex use cases or even have the ability to deploy a test stack directly from the canvas. There are many limitations at present, but perhaps that is somewhat of a biased point-of-view as we are not the prime audience for such a tool at this time. In particular for new serverless developers, whilst the tool can help with getting started and learning IaC, it needs to be used with some caution and assumptions upfront that it will require customisations on top and that one size doesn’t fit all.
As always, if you need help with your AWS projects, don’t hesitate to reach out to us, we’d love to help!
The full code for the quotes API service we’ve used in this post can be found on GitHub here – https://github.com/fourTheorem/application-composer-quotes-api-demo.